

Question: Project 2 :Please answer each question after the blue Answer Classification In this classification setting, we use a wine dataset of chemical measurement of two
Project 2:Please answer each question after the blue "Answer"
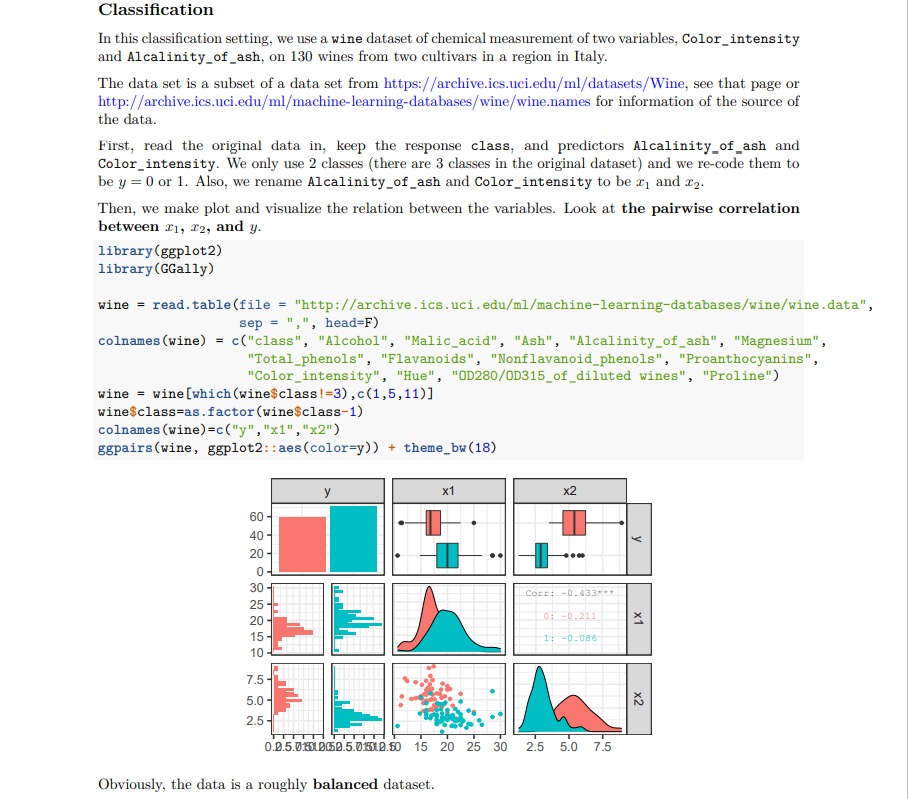

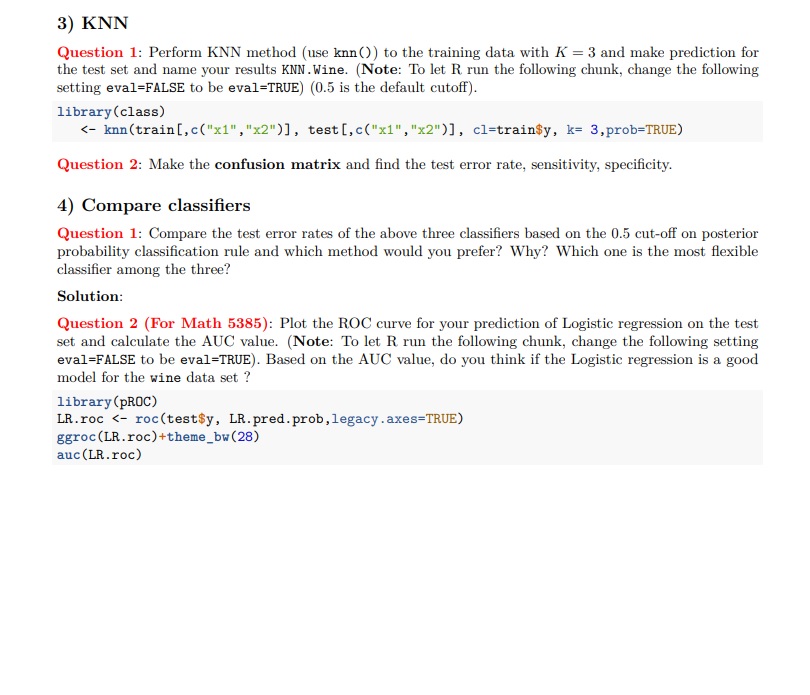
Step by Step Solution
There are 3 Steps involved in it
1 Expert Approved Answer
Step: 1 Unlock

Question Has Been Solved by an Expert!
Get step-by-step solutions from verified subject matter experts
Step: 2 Unlock
Step: 3 Unlock