

Question: PYTHON ONLY PLEASE FOLLOW DIRECTIONS! DIRECTIONS: import stdio import sys from markov_model import MarkovModel # Takes an integer k (model order) and a string s
PYTHON ONLY PLEASE FOLLOW DIRECTIONS!
DIRECTIONS:
import stdio import sys from markov_model import MarkovModel
# Takes an integer k (model order) and a string s (noisy message) as # command-line arguments, reads the input text from standard input, and # prints out the most likely original string. def main(): ...
if __name__ == '__main__': main()
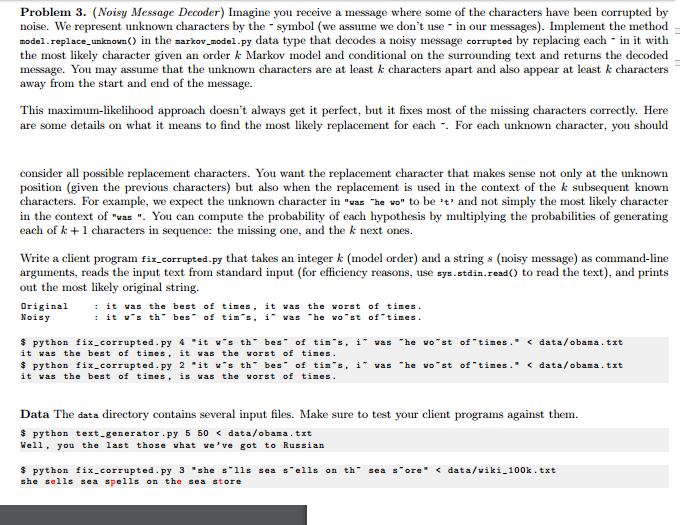
Problem 3. (Noisy Message Decoder) Imagine you receive a message where some of the characters have been corrupted by noise. We represent unknown characters by the symbol (we assume we don't use in our messages). Implement the method model-replace-unknown o in the markov model.py data type that decodes a noisy message corrupted by replacing each in it with the most likely character given an order k Markov model and conditional on the surrounding text and returns the decoded message. You may assume that the unknown characters are at least k characters apart and also appear at least k characters away from the start and end of the message. This maximum-likelihood approach doesn't always get it perfect, but it fixes most of the missing characters correctly. Here are some details on what it means to find the most likely replacement for each For each unknown character, you should consider all possible replacement characters. You want the replacement character that makes sense not only at the unknown position ven the previous characters) but also when the replacement is used in the context of the k subsequent known characters. For example, we expect the unknown character in "vas he vo" to be and not simply the most likely character in the context of "was You can compute the probability of each hypothesis by multiplying the probabilities of generating each of k l characters in sequence: the missing one, and the k next ones Write a client program fix-corrupted. Py that takes an integer k (model order) and a string s (noisy message) as command-line arguments, reads the input text from standard input (for efficiency reasons, use sys.stdin.reado to read the text), and prints out the most likely original string. Original it the best of times it was the worst of times Nois its v s th bes of tim s he of times python fix-corrupted py 4 it w's th bes of tin's i was he vo st of tines data/obama txt it was the best f times the of times python fix-corrupted py 2 it w's th bes f tin's, i was he vo st of tines data/obama .trt it was the best f times is the of times Data The data directory contains several input files. Make sure to test your client programs against them. python text-generator .py 5 50 data/obama. .trt Well the last those what t to Russian ve go python fix-corrupted py 3 she s 11 s sea s ells on th sea s ore data /viki-1 txt 00k she sells sea spells on the Problem 3. (Noisy Message Decoder) Imagine you receive a message where some of the characters have been corrupted by noise. We represent unknown characters by the symbol (we assume we don't use in our messages). Implement the method model-replace-unknown o in the markov model.py data type that decodes a noisy message corrupted by replacing each in it with the most likely character given an order k Markov model and conditional on the surrounding text and returns the decoded message. You may assume that the unknown characters are at least k characters apart and also appear at least k characters away from the start and end of the message. This maximum-likelihood approach doesn't always get it perfect, but it fixes most of the missing characters correctly. Here are some details on what it means to find the most likely replacement for each For each unknown character, you should consider all possible replacement characters. You want the replacement character that makes sense not only at the unknown position ven the previous characters) but also when the replacement is used in the context of the k subsequent known characters. For example, we expect the unknown character in "vas he vo" to be and not simply the most likely character in the context of "was You can compute the probability of each hypothesis by multiplying the probabilities of generating each of k l characters in sequence: the missing one, and the k next ones Write a client program fix-corrupted. Py that takes an integer k (model order) and a string s (noisy message) as command-line arguments, reads the input text from standard input (for efficiency reasons, use sys.stdin.reado to read the text), and prints out the most likely original string. Original it the best of times it was the worst of times Nois its v s th bes of tim s he of times python fix-corrupted py 4 it w's th bes of tin's i was he vo st of tines data/obama txt it was the best f times the of times python fix-corrupted py 2 it w's th bes f tin's, i was he vo st of tines data/obama .trt it was the best f times is the of times Data The data directory contains several input files. Make sure to test your client programs against them. python text-generator .py 5 50 data/obama. .trt Well the last those what t to Russian ve go python fix-corrupted py 3 she s 11 s sea s ells on th sea s ore data /viki-1 txt 00k she sells sea spells on the
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts