

Question: PYTHON PROBLEM For this problem, create a dictionary document_index that has the vocabulary in corpus as keys and for each vocabulary word, the value will
PYTHON PROBLEM
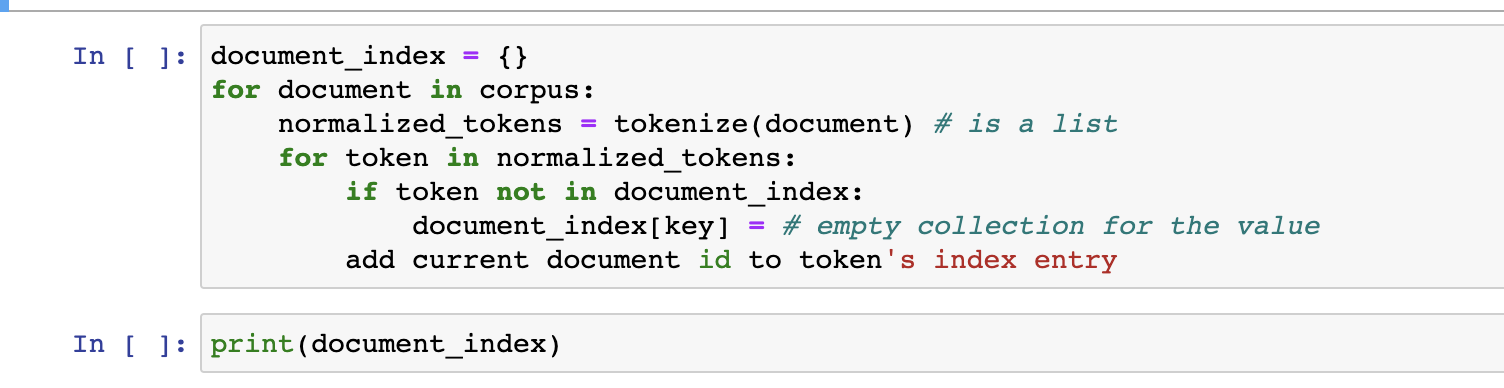
For this problem, create a dictionary document_index that has the vocabulary in corpus as keys and for each vocabulary word, the value will be the list of document id's containing that corpus. The final answer (the contents of document_index are shown at the end to help you visualize the data structure and determine if your code worked or not.
Some other information or hints/tips:
split on whitespace like we've seen for tokenization
convert to lowercase like we've seen for normalization
use the documents index in the corpus as an id. 0 for first doc, 1 for second, and so on
please show screenshot of output of code
{'i427': [0], 'search': [0], 'informatics': [0, 2], 'i308': [1], 'information': [1, 3], 'representation': [1], 'i101': [2], 'introduction': [2], 'to': [2], 'systems': [3]}
Please show a screenshot of your output, this is my third time uploading this question!
In [ ] : print(document_index)
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts