

Question: python, this code do not work, please help Write a function score_document (document, lang_counts=default_lang_counts) which takes as input a document name as a string and
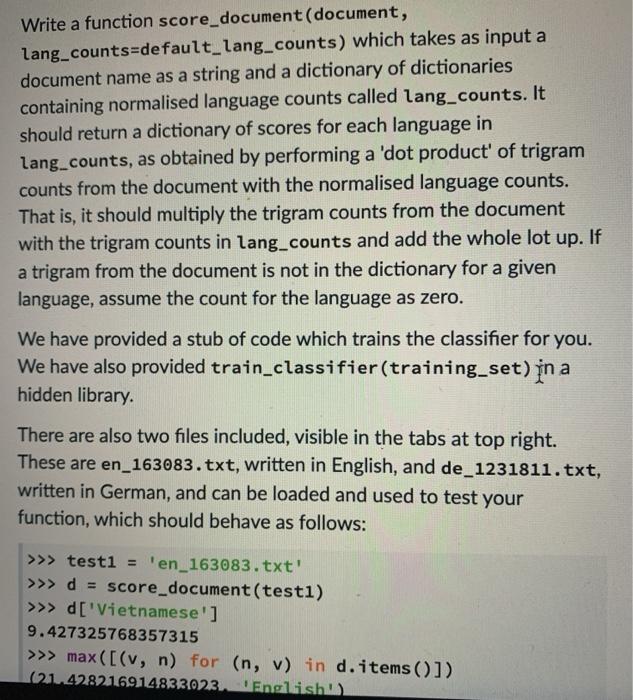
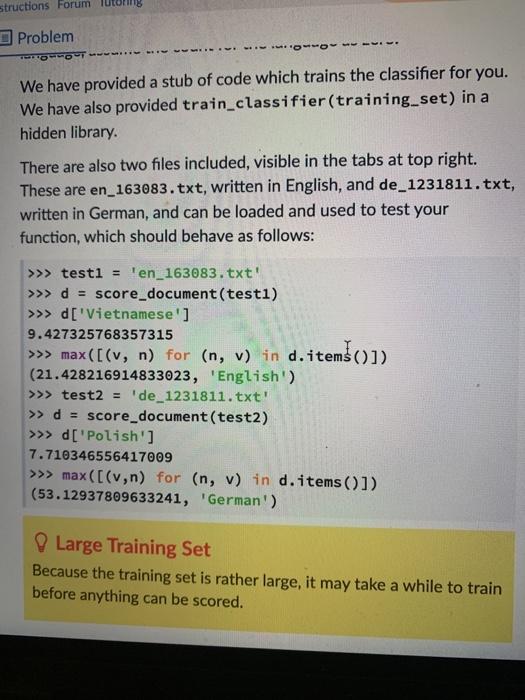
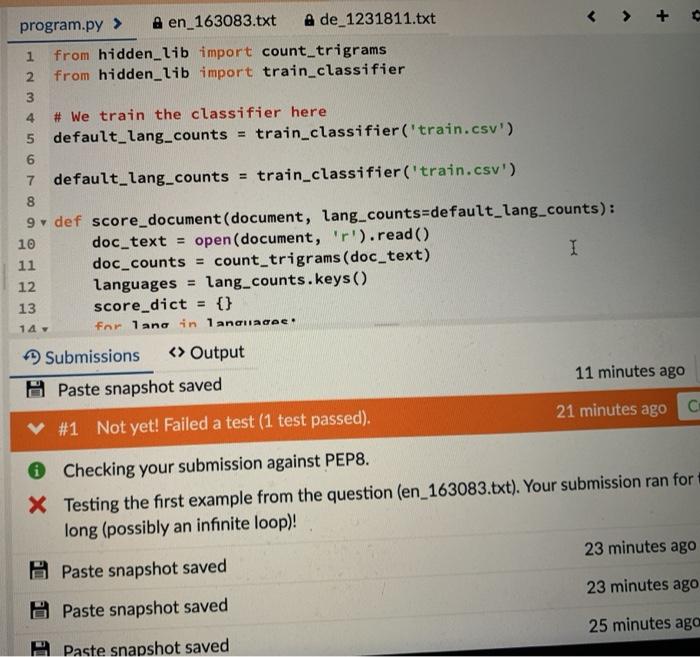
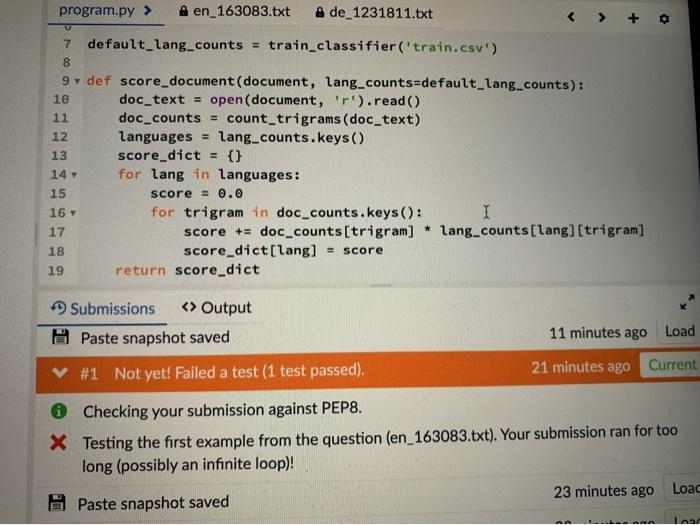
Write a function score_document (document, lang_counts=default_lang_counts) which takes as input a document name as a string and a dictionary of dictionaries containing normalised language counts called lang_counts. It should return a dictionary of scores for each language in lang_counts, as obtained by performing a 'dot product' of trigram counts from the document with the normalised language counts. That is, it should multiply the trigram counts from the document with the trigram counts in lang_counts and add the whole lot up. If a trigram from the document is not in the dictionary for a given language, assume the count for the language as zero. We have provided a stub of code which trains the classifier for you. We have also provided train_classifier(training set) in a hidden library There are also two files included, visible in the tabs at top right. These are en_163083.txt, written in English, and de_1231811. txt, written in German, and can be loaded and used to test your function, which should behave as follows: >>> testi = 'en_163083.txt' >>> d = score_document(testi) >>> d['Vietnamese'] 9.427325768357315 >>> max([(v, n) for (n, v) in d. items()]) (21.428216914833023. English structions Forum :: : - Problem RODOT. We have provided a stub of code which trains the classifier for you. We have also provided train_classifier(training set) in a hidden library. There are also two files included, visible in the tabs at top right. These are en_163083.txt, written in English, and de_1231811. txt, written in German, and can be loaded and used to test your function, which should behave as follows: >>> testi = 'en_163083.txt' >>> d = score_document(testi) >>> d['Vietnamese'] 9.427325768357315 >>> max ([(v, n) for (n, v) in d.item(1) (21.428216914833023, 'English') >>> test2 = 'de_1231811.txt" >> d = score_document (test2) >>> d['Polish'] 7.710346556417009 >>> max([(v,n) for (n, v) in d.items()]) (53.12937809633241, 'German') Large Training Set Because the training set is rather large, it may take a while to train before anything can be scored. + 4 program.py > A en_163083.txt A de_1231811.txt 1 from hidden_lib import count_trigrams 2 from hidden_lib import train_classifier 3 # We train the classifier here 5 default_lang_counts = train_classifier('train.csv') 6 7 default_lang_counts = train_classifier('train.csv') 8 9 def score_document (document, lang_counts=default_lang_counts): 10 doc_text = open(document, 'r').read() 11 doc_counts = count_trigrams (doc_text) I 12 languages = lang_counts.keys () 13 score_dict = {} for lang in language. Submissions Output Paste snapshot saved 11 minutes ago 21 minutes ago C V #1 Not yet! Failed a test (1 test passed). 14 6 Checking your submission against PEP8. X Testing the first example from the question (en_163083.txt). Your submission ran for long (possibly an infinite loop)! 23 minutes ago Paste snapshot saved 23 minutes ago Paste snapshot saved 25 minutes ago TE Paste snapshot saved program.py > en_163083.txt A de_1231811.txt 7 default_lang_counts = train_classifier('train.csv") 8 9 def score_document (document, lang_counts=default_lang_counts): 10 doc_text = open(document, 'r').read() 11 doc_counts = count_trigrams (doc_text) 12 languages lang_counts.keys() 13 score_dict {} 14 for lang in languages: 15 score = 0.0 16 for trigram in doc_counts.keys(): I 17 score += doc_counts[trigram] * lang_counts[lang][trigram] 18 score_dict[lang] = score 19 return score_dict 1 Submissions Output Paste snapshot saved #1 Not yet! Failed a test (1 test passed). 11 minutes ago Load 21 minutes ago Current Checking your submission against PEP8. X Testing the first example from the question (en_163083.txt). Your submission ran for too long (possibly an infinite loop)! Paste snapshot saved 23 minutes ago Loac Taar
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts