

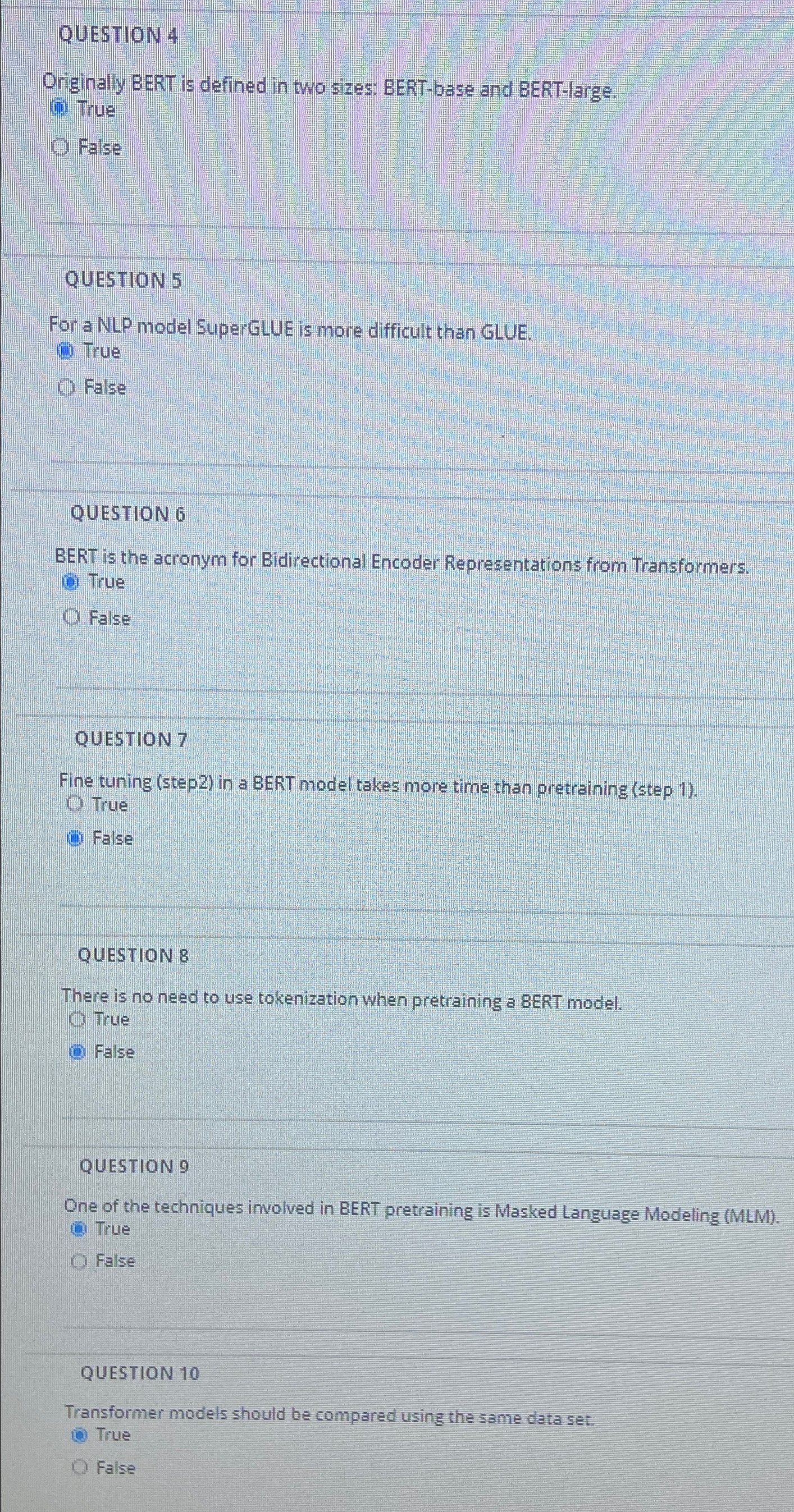
Question: QUESTION 4 Originally BERT is defined in two sizes: BERT - base and BERT - large. ( 6 ) True O False QUESTION 5 For
QUESTION
Originally BERT is defined in two sizes: BERTbase and BERTlarge.
True
O False
QUESTION
For a NLP model SuperGLUE is more difficult than GLUE.
True
False
QUESTION
BERT is the acronym for Bidirectional Encoder Representations from Transformers.
True
O False
QUESTION
Fine tuning step in a BERT model takes more time than pretraining step
True
False
QUESTION
There is no need to use tokenization when pretraining a BERT model.
True
False
QUESTION
One of the techniques involved in BERT pretraining is Masked Language Modeling MLM
True
False
QUESTION
Transformer models should be compared using the same data set.
True
False
Step by Step Solution
There are 3 Steps involved in it
1 Expert Approved Answer
Step: 1 Unlock

Question Has Been Solved by an Expert!
Get step-by-step solutions from verified subject matter experts
Step: 2 Unlock
Step: 3 Unlock