

Question: - Reddit Context: Andres really likes cooking. Trying to find something new to cook, Andres finds a subreddit where people share and talk about recipes:



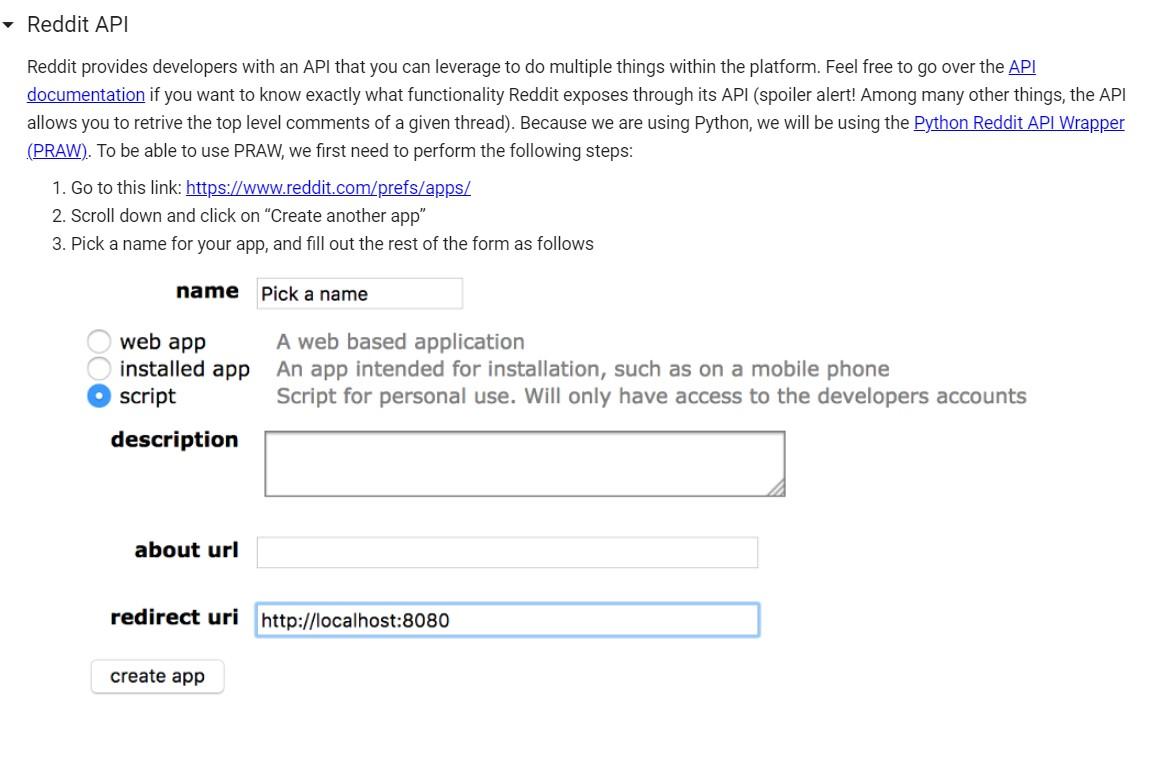
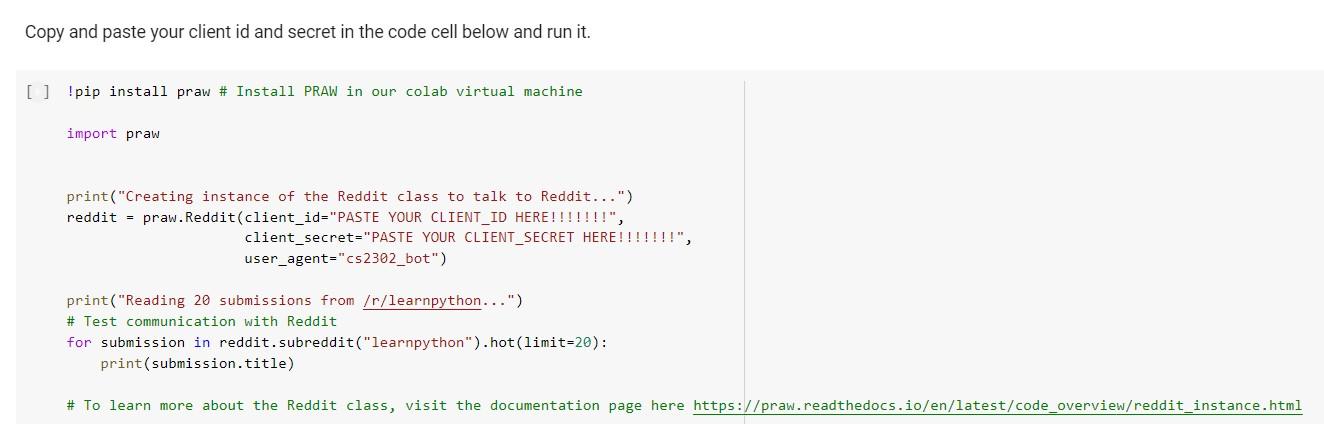
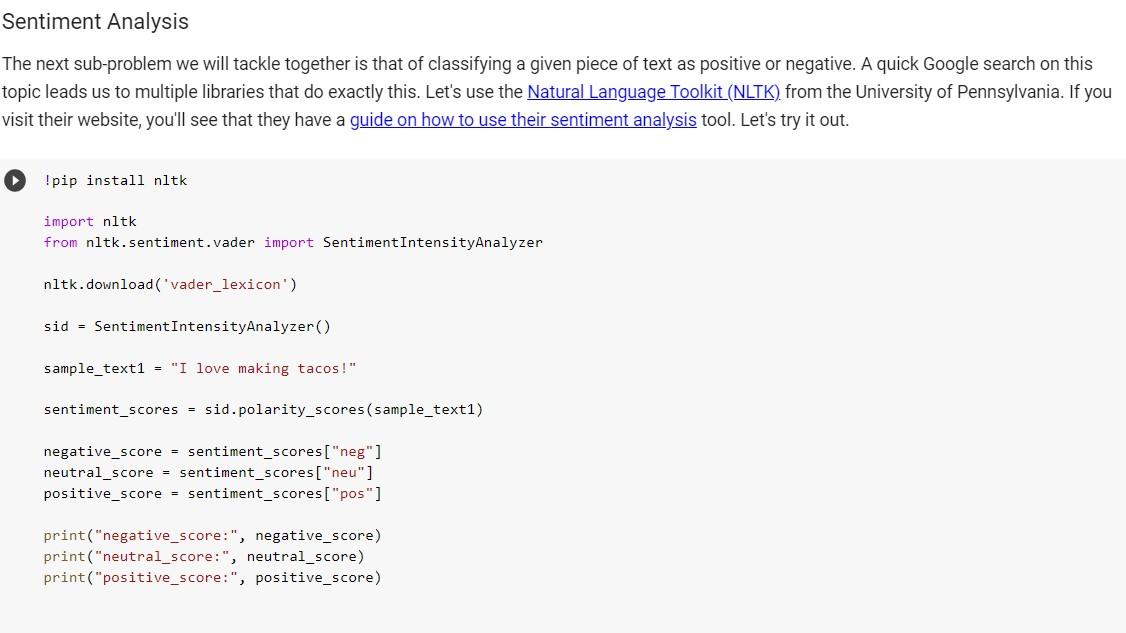
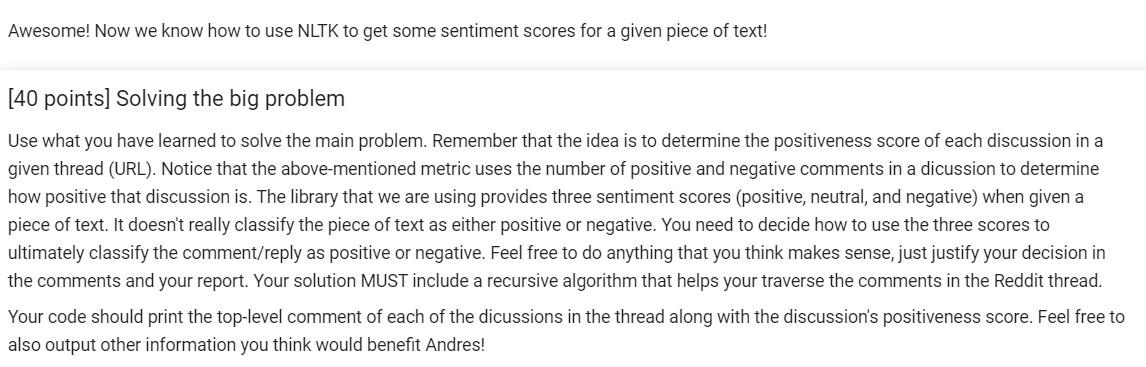
- Reddit Context: Andres really likes cooking. Trying to find something new to cook, Andres finds a subreddit where people share and talk about recipes: /r/recipes. After browsing the subreddit for a while, he realizes that people have all sorts of conversations about a recipe (some positive and some negative). Andres wants to try the recipes that contain mostly positive discussions first. He wants to 1) identify all the discussions people are having about a specific recipe, and 2) determine how positive each of these discussions is. Andres knows you are a great problem-solver, so he asks you to write a program that, given the URL to a specific Reddit thread, reads the different discussions people are having and assigns them a score based on how positive they are. To make things easier, you decide to make the assumption that each top level comment is the start of a discussion. That is, the thread is assumed to have as many discussions as there are top level comments. For example, let's say that you have the following thread: | Top Level Comment 1 Reply 1.1 Reply 1.1.1 Reply 1.1.1.1 Reply 1.1.2 Reply 1.1.3 Reply 1.2 | Reply 1.3 | Top Level Comment 2 11 Reply 2.1 11 Reply 2.2 11 Reply 2.3 Reply 2.3.1 Reply 2.3.2 In this particular example, there are 3 top level comments, meaning that we are dealing with 3 different discussions. For illustration purposes, each discussion is represented with a different color. To determine how positive a given discussion is, you decide to use the following metric: number of positive comments number of positive comments + number of negative comments For example, let's say you're trying to determine how positive dicussion 1 is. The first step would be to classify every comment in the discussion independently, and then use the above-mentioned metric. Let's assume that classifying each comment in the discussion yields the following results: Positive Comments: Top Comment 1, Reply 1.1, Reply 1.1.2, Reply 1.1.3, and Reply 1.3 Negative Comments: Reply 1.1.1, Reply 1.1.1,1, and Reply 1.2 Number of positive comments: 5 Number of negative comments: 3 Discussion 1 positiveness score: 343 = 5 Your job is to compute and display (print) the positiveness score of all discussions in a thread given its URL. Problem Decomposition In order to help Andres, we need to decompose the problem into smaller problems. Often, when we decompose a problem, the subproblems come as questions or tasks that need to be dealt with. If these questions/tasks are too abstract or complex, they need to broken down even further into smaller sub-tasks. Here's a list of questions you might be asking yourself right now: 1. Given the URL to a Reddit thread, how can I read its top level comments? Does Reddit have an API? If so, how does it work? 2. Top level comments in a given thread have replies, and those replies have replies, and those have replies as well! The number of levels is unknown. How can my code traverse this recursive structure? 3. Given a Reddit comment/reply, how can I classify it as either positive or negative? This sounds complex! Is there a library that can do this for me? If so, how can I integrate it into my project? 4. What useful information can I collect as the data is processed? What would help Andres explore the inmense sea of recipes in the subreddit? Let's solve some of these sub-problems together. Reddit API Reddit provides developers with an API that you can leverage to do multiple things within the platform. Feel free to go over the API documentation if you want to know exactly what functionality Reddit exposes through its API (spoiler alert! Among many other things, the API allows you to retrive the top level comments of a given thread). Because we are using Python, we will be using the Python Reddit API Wrapper (PRAW). To be able to use PRAW, we first need to perform the following steps: 1. Go to this link: https://www.reddit.com/prefs/apps/ 2. Scroll down and click on "Create another app" 3. Pick a name for your app, and fill out the rest of the form as follows name Pick a name web app installed app script A web based application An app intended for installation, such as on a mobile phone Script for personal use. Will only have access to the developers accounts description about url redirect uri http://localhost:8080 create app Copy and paste your client id and secret in the code cell below and run it. [ ] !pip install praw # Install PRAW in our colab virtual machine import praw print("Creating instance of the Reddit class to talk to Reddit...") reddit = praw.Reddit(client_id="PASTE YOUR CLIENT_ID HERE!!!!!!!", client_secret="PASTE YOUR CLIENT_SECRET HERE!!!!!!!", user_agent="cs2302_bot") print("Reading 20 submissions from /r/learnpython...") # Test communication with Reddit for submission in reddit. subreddit("learnpython").hot(limit=20): print( submission.title) # To learn more about the Reddit class, visit the documentation page here https://praw.readthedocs.io/en/latest/code_overview/reddit_instance.html Sentiment Analysis The next sub-problem we will tackle together is that of classifying a given piece of text as positive or negative. A quick Google search on this topic leads us to multiple libraries that do exactly this. Let's use the Natural Language Toolkit (NLTK) from the University of Pennsylvania. If you visit their website, you'll see that they have a guide on how to use their sentiment analysis tool. Let's try it out. !pip install nltk import nltk from nltk. sentiment.vader import Sentiment IntensityAnalyzer nltk.download('vader_lexicon) sid - Sentiment IntensityAnalyzer() sample_text1 = "I love making tacos!" sentiment_scores = sid.polarity_scores (sample_text1) negative_score = sentiment_scores ["neg" ] neutral_score = sentiment_scores ["neu" ] positive_score = sentiment_scores ["pos" ] print("negative_score:", negative_score) print("neutral_score:", neutral_score) print("positive_score:", positive_score) Awesome! Now we know how to use NLTK to get some sentiment scores for a given piece of text! [40 points] Solving the big problem Use what you have learned to solve the main problem. Remember that the idea is to determine the positiveness score of each discussion in a given thread (URL). Notice that the above-mentioned metric uses the number of positive and negative comments in a dicussion to determine how positive that discussion is. The library that we are using provides three sentiment scores (positive, neutral, and negative) when given a piece of text. It doesn't really classify the piece of text as either positive or negative. You need to decide how to use the three scores to ultimately classify the comment/reply as positive or negative. Feel free to do anything that you think makes sense, just justify your decision in the comments and your report. Your solution MUST include a recursive algorithm that helps your traverse the comments in the Reddit thread. Your code should print the top-level comment of each of the dicussions in the thread along with the discussion's positiveness score. Feel free to also output other information you think would benefit Andres! - Reddit Context: Andres really likes cooking. Trying to find something new to cook, Andres finds a subreddit where people share and talk about recipes: /r/recipes. After browsing the subreddit for a while, he realizes that people have all sorts of conversations about a recipe (some positive and some negative). Andres wants to try the recipes that contain mostly positive discussions first. He wants to 1) identify all the discussions people are having about a specific recipe, and 2) determine how positive each of these discussions is. Andres knows you are a great problem-solver, so he asks you to write a program that, given the URL to a specific Reddit thread, reads the different discussions people are having and assigns them a score based on how positive they are. To make things easier, you decide to make the assumption that each top level comment is the start of a discussion. That is, the thread is assumed to have as many discussions as there are top level comments. For example, let's say that you have the following thread: | Top Level Comment 1 Reply 1.1 Reply 1.1.1 Reply 1.1.1.1 Reply 1.1.2 Reply 1.1.3 Reply 1.2 | Reply 1.3 | Top Level Comment 2 11 Reply 2.1 11 Reply 2.2 11 Reply 2.3 Reply 2.3.1 Reply 2.3.2 In this particular example, there are 3 top level comments, meaning that we are dealing with 3 different discussions. For illustration purposes, each discussion is represented with a different color. To determine how positive a given discussion is, you decide to use the following metric: number of positive comments number of positive comments + number of negative comments For example, let's say you're trying to determine how positive dicussion 1 is. The first step would be to classify every comment in the discussion independently, and then use the above-mentioned metric. Let's assume that classifying each comment in the discussion yields the following results: Positive Comments: Top Comment 1, Reply 1.1, Reply 1.1.2, Reply 1.1.3, and Reply 1.3 Negative Comments: Reply 1.1.1, Reply 1.1.1,1, and Reply 1.2 Number of positive comments: 5 Number of negative comments: 3 Discussion 1 positiveness score: 343 = 5 Your job is to compute and display (print) the positiveness score of all discussions in a thread given its URL. Problem Decomposition In order to help Andres, we need to decompose the problem into smaller problems. Often, when we decompose a problem, the subproblems come as questions or tasks that need to be dealt with. If these questions/tasks are too abstract or complex, they need to broken down even further into smaller sub-tasks. Here's a list of questions you might be asking yourself right now: 1. Given the URL to a Reddit thread, how can I read its top level comments? Does Reddit have an API? If so, how does it work? 2. Top level comments in a given thread have replies, and those replies have replies, and those have replies as well! The number of levels is unknown. How can my code traverse this recursive structure? 3. Given a Reddit comment/reply, how can I classify it as either positive or negative? This sounds complex! Is there a library that can do this for me? If so, how can I integrate it into my project? 4. What useful information can I collect as the data is processed? What would help Andres explore the inmense sea of recipes in the subreddit? Let's solve some of these sub-problems together. Reddit API Reddit provides developers with an API that you can leverage to do multiple things within the platform. Feel free to go over the API documentation if you want to know exactly what functionality Reddit exposes through its API (spoiler alert! Among many other things, the API allows you to retrive the top level comments of a given thread). Because we are using Python, we will be using the Python Reddit API Wrapper (PRAW). To be able to use PRAW, we first need to perform the following steps: 1. Go to this link: https://www.reddit.com/prefs/apps/ 2. Scroll down and click on "Create another app" 3. Pick a name for your app, and fill out the rest of the form as follows name Pick a name web app installed app script A web based application An app intended for installation, such as on a mobile phone Script for personal use. Will only have access to the developers accounts description about url redirect uri http://localhost:8080 create app Copy and paste your client id and secret in the code cell below and run it. [ ] !pip install praw # Install PRAW in our colab virtual machine import praw print("Creating instance of the Reddit class to talk to Reddit...") reddit = praw.Reddit(client_id="PASTE YOUR CLIENT_ID HERE!!!!!!!", client_secret="PASTE YOUR CLIENT_SECRET HERE!!!!!!!", user_agent="cs2302_bot") print("Reading 20 submissions from /r/learnpython...") # Test communication with Reddit for submission in reddit. subreddit("learnpython").hot(limit=20): print( submission.title) # To learn more about the Reddit class, visit the documentation page here https://praw.readthedocs.io/en/latest/code_overview/reddit_instance.html Sentiment Analysis The next sub-problem we will tackle together is that of classifying a given piece of text as positive or negative. A quick Google search on this topic leads us to multiple libraries that do exactly this. Let's use the Natural Language Toolkit (NLTK) from the University of Pennsylvania. If you visit their website, you'll see that they have a guide on how to use their sentiment analysis tool. Let's try it out. !pip install nltk import nltk from nltk. sentiment.vader import Sentiment IntensityAnalyzer nltk.download('vader_lexicon) sid - Sentiment IntensityAnalyzer() sample_text1 = "I love making tacos!" sentiment_scores = sid.polarity_scores (sample_text1) negative_score = sentiment_scores ["neg" ] neutral_score = sentiment_scores ["neu" ] positive_score = sentiment_scores ["pos" ] print("negative_score:", negative_score) print("neutral_score:", neutral_score) print("positive_score:", positive_score) Awesome! Now we know how to use NLTK to get some sentiment scores for a given piece of text! [40 points] Solving the big problem Use what you have learned to solve the main problem. Remember that the idea is to determine the positiveness score of each discussion in a given thread (URL). Notice that the above-mentioned metric uses the number of positive and negative comments in a dicussion to determine how positive that discussion is. The library that we are using provides three sentiment scores (positive, neutral, and negative) when given a piece of text. It doesn't really classify the piece of text as either positive or negative. You need to decide how to use the three scores to ultimately classify the comment/reply as positive or negative. Feel free to do anything that you think makes sense, just justify your decision in the comments and your report. Your solution MUST include a recursive algorithm that helps your traverse the comments in the Reddit thread. Your code should print the top-level comment of each of the dicussions in the thread along with the discussion's positiveness score. Feel free to also output other information you think would benefit Andres
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts