

Question: Semi - Gradient Update This problem presents a brief glimpse of the problems that can arise in off - policy learning with function approximation, through
SemiGradient Update
This problem presents a brief glimpse of the problems that can arise in offpolicy learning with function approximation, through the concepts that have been introduced so far. If
you would like a more detailed discussion on these issues, you may refer to Chapter Let us now apply semigradient TD learning from Chapter with batch updates Section
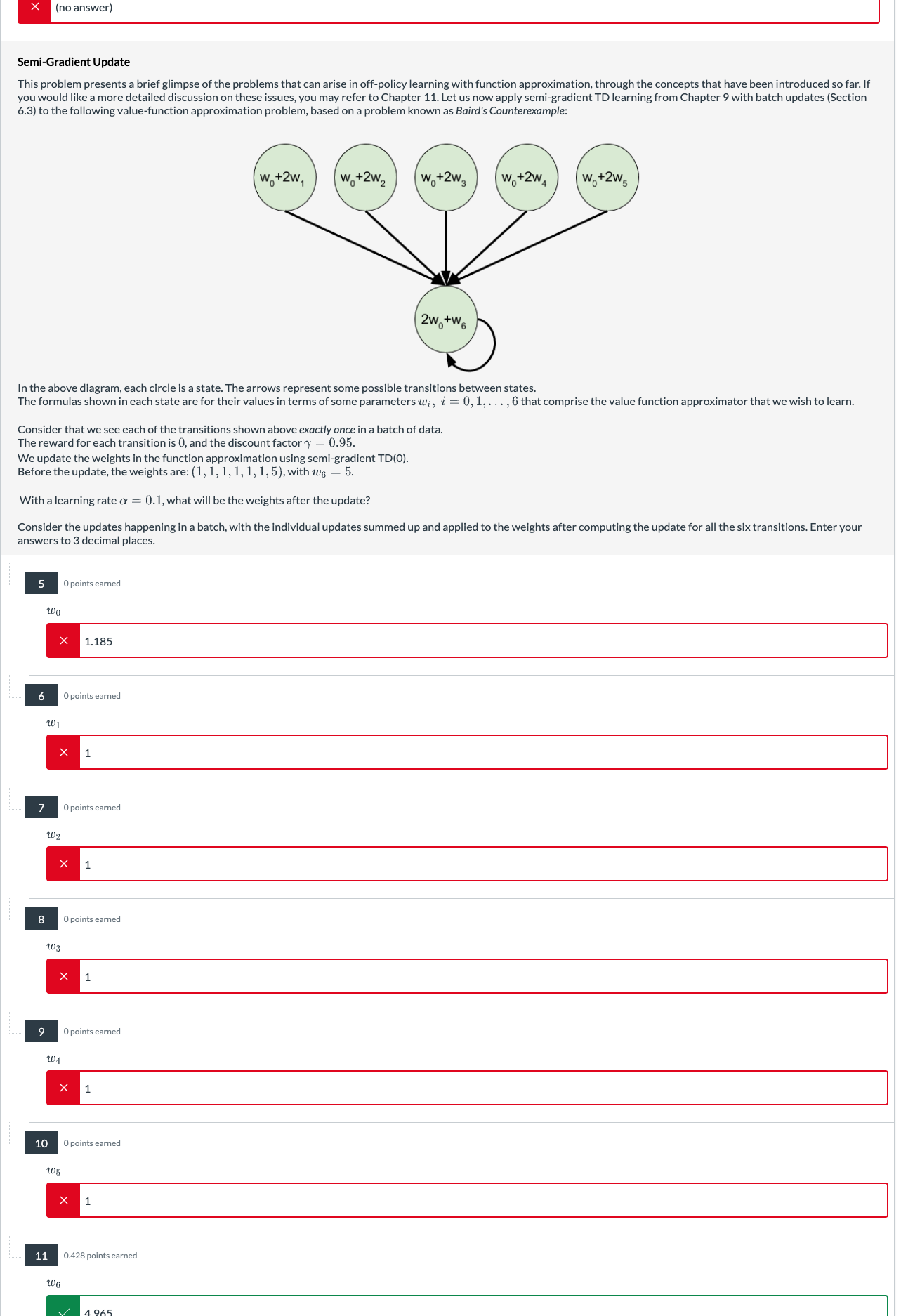
to the following valuefunction approximation problem, based on a problem known as Baird's Counterexample:
In the above diagram, each circle is a state. The arrows represent some possible transitions between states.
The formulas shown in each state are for their values in terms of some parameters dots, that comprise the value function approximator that we wish to learn.
Consider that we see each of the transitions shown above exactly once in a batch of data.
The reward for each transition is and the discount factor
We update the weights in the function approximation using semigradient TD
Before the update, the weights are: with
With a learning rate what will be the weights after the update?
Consider the updates happening in a batch, with the individual updates summed up and applied to the weights after computing the update for all the six transitions. Enter your
answers to decimal places.
points earned
points earned
points earned
points earned
O points earned
points earned
Step by Step Solution
There are 3 Steps involved in it
1 Expert Approved Answer
Step: 1 Unlock

Question Has Been Solved by an Expert!
Get step-by-step solutions from verified subject matter experts
Step: 2 Unlock
Step: 3 Unlock