

Question: The following cell defines a regular expression for a simple tokenizer. As written, it divides tokens up at spaces with two exceptions: punctuation marks are
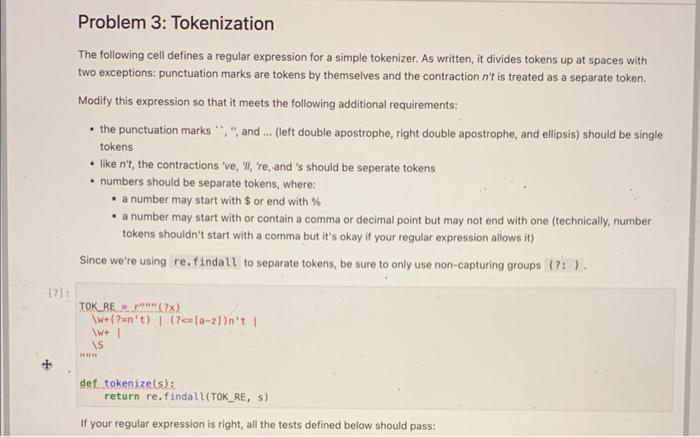
The following cell defines a regular expression for a simple tokenizer. As written, it divides tokens up at spaces with two exceptions: punctuation marks are tokens by themselves and the contraction n 't is treated as a separate token. Modify this expression so that it meets the following additional requirements: - the punctuation marks ,", and ... (left double apostrophe, right double apostrophe, and ellipsis) should be single tokens - like n 't, the contractions 've, 'II, 're, and 's should be seperate tokens - numbers should be separate tokens, where: - a number may start with $ or end with \% - a number may start with or contain a comma or decimal point but may not end with one (technically, number tokens shouldn't start with a comma but it's okay if your regular expression aliows it) Since we're using re.findalt to separate tokens, be sure to only use non-capturing groups (?:) )
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts