

Question: The function get_most_relevant takes two arguments: docs, documents, in the form of a dictionary (keys and values are both strings) and query in the form


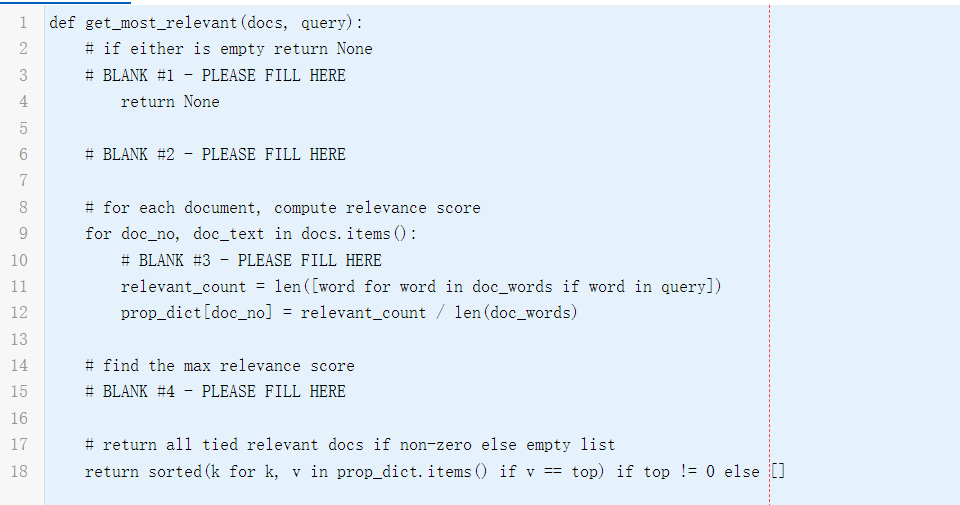
The function get_most_relevant takes two arguments: docs, documents, in the form of a dictionary (keys and values are both strings) and query in the form of a tuple of strings, and returns the list with document(s) having the highest relevance score. The relevance score is based on the number of times the provided query terms (words) appear in the corresponding document. More specifically, we define term frequency (TF) to be the frequency of a term t in a document d divided by the number of words in the document d. As an equation, this is TF=f(t,d)/ len (d) where f(t,d) is the frequency of term t (query word) in the document d and len (d) is the total count of terms (words) in the document d. If some term t does not appear in the document string, its score should be 0 , and it does not contribute to the relevance score. You should assume that sentences do not contain punctuation and words can be identified using white space. Documents should be lowercased. The query words are always provided in lowercase. If docs or query is empty, the function should return None. Some example calls to the function are: > get_most_relevant ({doc1:A cat sat on the mat', ', [ 'doc1', 'doc2'] get_most_relevant ({},()) None get_most_relevant(\{'doc1':'A cat sat on the mat', ', ['doc 2] get_most_relevant ({doc1:A cat sat on the mat', ', [] Provide one line of code in each blank to complete the function! Write your answers by replacing each "BLANK \#" comment with the correct line of code in the editor. def get_most_relevant(docs, query): \# if either is empty return None \# BLANK \#1 - PLEASE FILL HERE return None \# BLANK \#2 - PLEASE FILL HERE \# for each document, compute relevance score for doc_no, doc_text in docs.items(): \# BLANK \#3 - PLEASE FILL HERE relevant_count = len([word for word in doc_words if word in query]) prop_no] = relevant_count / len (doc_words) \# find the max relevance score \# BLANK \#4 - PLEASE FILL HERE \# return all tied relevant docs if non-zero else empty list return sorted(k for k, v in prop_dict.items() if v == top) if top != 0 else
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts