

Question: The Input image size is (28,28). Context Aggregation Networks (CAN) (25 points) We can also implement a simple CNN model with dilated convolutions. We can
The Input image size is (28,28).

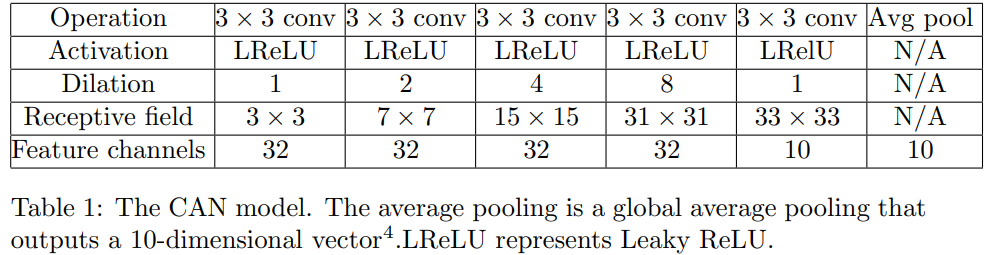
Context Aggregation Networks (CAN) (25 points) We can also implement a simple CNN model with dilated convolutions. We can have a model with a large receptive field with the same spatial resolution in the hidden layers. See the network architecture in the Table 1. For your information, the dilated residual network 2 is a similar model for image classification. Table 1: The CAN model. The average pooling is a global average pooling that outputs a 10-dimensional vector 4.LReLU represents Leaky ReLU
Step by Step Solution
There are 3 Steps involved in it
1 Expert Approved Answer
Step: 1 Unlock

Question Has Been Solved by an Expert!
Get step-by-step solutions from verified subject matter experts
Step: 2 Unlock
Step: 3 Unlock