Question: The simple C code given below is vectorized for RV64V in the following assembly code. C Code: float a[n],b[n]; / is some constant which students
The simple C code given below is vectorized for RV64V in the following assembly code.
C Code:
float a[n],b[n]; / is some constant which students have to determine
double c[n];
for (i=0; i c[i]=a[i]*b[i];
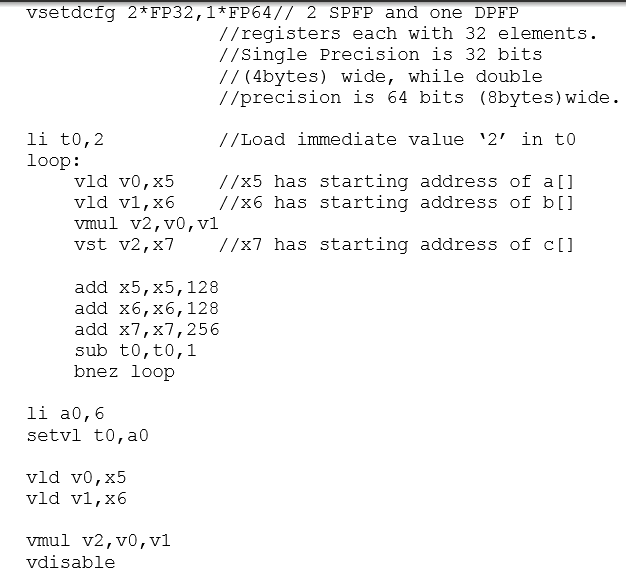
![following assembly code. C Code: float a[n],b[n]; / is some constant which](https://dsd5zvtm8ll6.cloudfront.net/si.experts.images/questions/2024/09/66f39ab705500_88666f39ab69518f.jpg)
vsetdcfg 2*FP32,1*FP64// 2 SPFP and one DPFP //registers each with 32 elements. //Single Precision is 32 bits // (4bytes) wide, while double //precision is 64 bits (8bytes) wide. li t0,2 //Load immediate value '2' in to loop: vld v0, x5 //x5 has starting address of a[] vld vi, X6 //x6 has starting address of b[] vmul v2,v0, vi vst v2,x7 //x7 has starting address of c[] add x5, x5, 128 add x6, x6, 128 add x7,x7,256 sub to, t0,1 bnez loop li a0,6 setvl to, a vld v0, x5 vld vi, X6 vmul v2,v0, v1 vdisable a) Determine the number of elements 'n' (the loop limit for C code) of the vectors by analyzing the assembly code. (5 b) The first four instructions inside the loop of assembly code will be executed by the vector extension. Show how they layout as convoy if we have only one copy of each vector functional unit with chaining (5 c) Calculate the execution time for the 4 instructions (just one iteration) that you already laid out as convoys, in chimes and clock cycles, ignoring the latencies. (5 d) If load, mul and store have latencies of 7,8, and 7 cycles respectively, (5 recalculate the execution time for these 4 instructions including the latencies. vsetdcfg 2*FP32,1*FP64// 2 SPFP and one DPFP //registers each with 32 elements. //Single Precision is 32 bits // (4bytes) wide, while double //precision is 64 bits (8bytes) wide. li t0,2 //Load immediate value '2' in to loop: vld v0, x5 //x5 has starting address of a[] vld vi, X6 //x6 has starting address of b[] vmul v2,v0, vi vst v2,x7 //x7 has starting address of c[] add x5, x5, 128 add x6, x6, 128 add x7,x7,256 sub to, t0,1 bnez loop li a0,6 setvl to, a vld v0, x5 vld vi, X6 vmul v2,v0, v1 vdisable a) Determine the number of elements 'n' (the loop limit for C code) of the vectors by analyzing the assembly code. (5 b) The first four instructions inside the loop of assembly code will be executed by the vector extension. Show how they layout as convoy if we have only one copy of each vector functional unit with chaining (5 c) Calculate the execution time for the 4 instructions (just one iteration) that you already laid out as convoys, in chimes and clock cycles, ignoring the latencies. (5 d) If load, mul and store have latencies of 7,8, and 7 cycles respectively, (5 recalculate the execution time for these 4 instructions including the latencies


