

Question: This is the example output below: The zip file text.zip contains the following texts, downloaded from Project Gutenberg and the Internet Archive. The texts haven't

This is the example output below: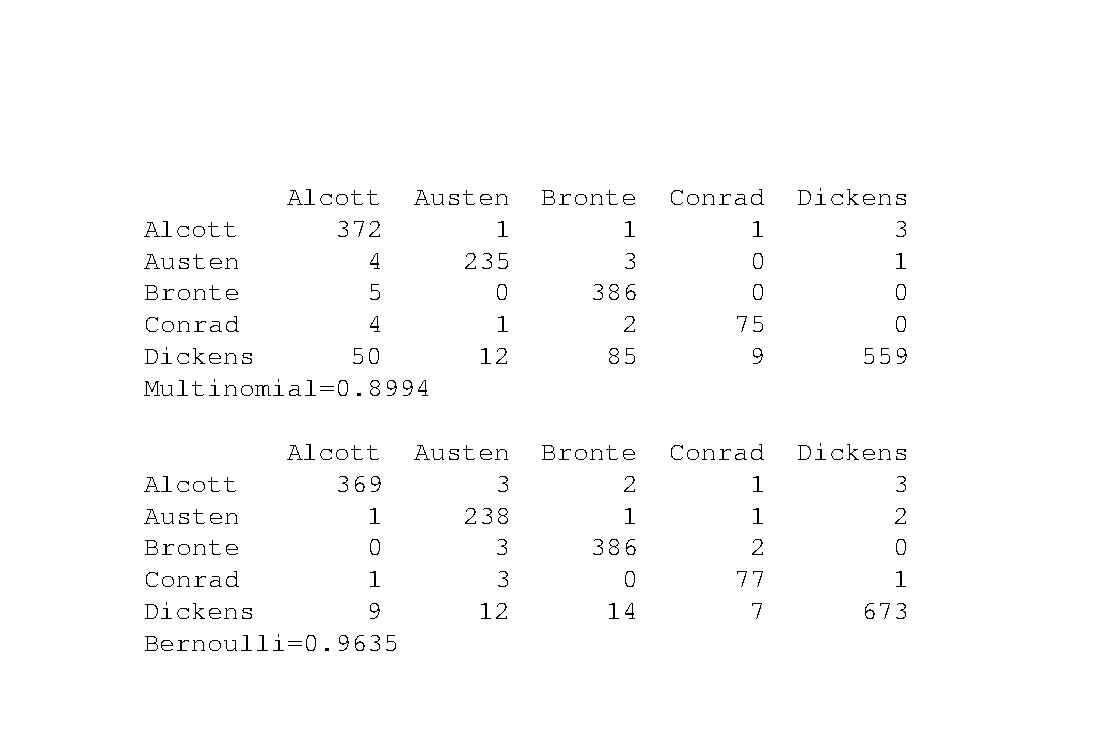
The zip file text.zip contains the following texts, downloaded from Project Gutenberg and the Internet Archive. The texts haven't been vetted and so might contain errors, objectionable material, etc. Test Files Alcott-Lousia May-Little Women.txt Austen-Jane-Sense and Sensibility.txt Bronte Charlotte-Villette.txt Conrad-Joseph-Heart of Darkness.txt Dickens-Charles David Copperfield.txt Training Files Alcott-Lousia May-Eight Cousins.txt Alcott-Lousia May-Jos Boys.txt Alcott-Lousia May-Little Men.txt Austen-Jane-Mansfield Park.txt Austen-Jane-Northanger Abbey.txt Austen-Jane-Persuasion.txt Austen-Jane-Pride and Prejudice.txt Bronte-Charlotte-Jane Eyre.txt Bronte-Charlotte Professor.txt Bronte-Charlotte-Shirley.txt Bronte-Charlotte-Villette.txt Conrad-Joseph-Lord Jim.txt Conrad-Joseph-Nostromo.txt Conrad-Joseph-Secret Agent.txt Conrad-Joseph-Secret Sharer.txt Dickens-Charles-Bleak House.txt Dickens-Charles-Christmas Carol.txt Dickens-Charles-Hard Times.txt Dickens-Charles-Life And Adventures Of Nicholas Nickleby.ext Dickens-Charles-Pickwick Papers.txt . For this assignment, use Python and sklearn.naive bayes to create classifiers to identify a text's author. Specifically, Write routines to tokenize the text, breaking each work into groups of 500 tokens (use NLTK's word_tokenize to perform the tokenization). Generate training and testing sets by associating the author of the work witch each sequence of 500 tokens. The prefix of the file name encodes the last and first name of the author. Afterwards, create classifiers using both MultinomialNB and BernoulliNB (See https:/lp.stanford.edu/IR- book/html/htmledition/the-bernoulli-modell.html) to map the token sequences to the author of the original text. Train and test the classifiers on the texts indicated above. Report the accuracy and generate a confusion matrix for each classifier. Experiment further, generating two additional classifiers. Can you improve the accuracy at all on the test set by, e.g., removing stop words, or re-sampling the training set to balance the classes ? Report the accuracy and generate a confusion matrix for the your modified classifiers. Ensure you program can be run, simply by invoking test (directory) where directory is the name of the directory holding the original text files. Your output should look something like the output shown on the next page (don't assume the numbers shown are reasonable Conrad 1 Dickens 3 0 1 Alcott Austen Alcott 372 1 Austen 4 235 Bronte 5 0 Conrad 4 1 Dickens 50 12 Multinomial=0.8994 Bronte 1 3 386 2 85 0 0 75 9 0 559 Alcott Alcott 369 Austen 1 Bronte 0 Conrad 1 Dickens 9 Bernoulli=0.9635 Austen 3 238 3 Bronte 2 1 386 0 14 Conrad 1 1 2 Dickens 3 2 0 1 3 12 7 673 The zip file text.zip contains the following texts, downloaded from Project Gutenberg and the Internet Archive. The texts haven't been vetted and so might contain errors, objectionable material, etc. Test Files Alcott-Lousia May-Little Women.txt Austen-Jane-Sense and Sensibility.txt Bronte Charlotte-Villette.txt Conrad-Joseph-Heart of Darkness.txt Dickens-Charles David Copperfield.txt Training Files Alcott-Lousia May-Eight Cousins.txt Alcott-Lousia May-Jos Boys.txt Alcott-Lousia May-Little Men.txt Austen-Jane-Mansfield Park.txt Austen-Jane-Northanger Abbey.txt Austen-Jane-Persuasion.txt Austen-Jane-Pride and Prejudice.txt Bronte-Charlotte-Jane Eyre.txt Bronte-Charlotte Professor.txt Bronte-Charlotte-Shirley.txt Bronte-Charlotte-Villette.txt Conrad-Joseph-Lord Jim.txt Conrad-Joseph-Nostromo.txt Conrad-Joseph-Secret Agent.txt Conrad-Joseph-Secret Sharer.txt Dickens-Charles-Bleak House.txt Dickens-Charles-Christmas Carol.txt Dickens-Charles-Hard Times.txt Dickens-Charles-Life And Adventures Of Nicholas Nickleby.ext Dickens-Charles-Pickwick Papers.txt . For this assignment, use Python and sklearn.naive bayes to create classifiers to identify a text's author. Specifically, Write routines to tokenize the text, breaking each work into groups of 500 tokens (use NLTK's word_tokenize to perform the tokenization). Generate training and testing sets by associating the author of the work witch each sequence of 500 tokens. The prefix of the file name encodes the last and first name of the author. Afterwards, create classifiers using both MultinomialNB and BernoulliNB (See https:/lp.stanford.edu/IR- book/html/htmledition/the-bernoulli-modell.html) to map the token sequences to the author of the original text. Train and test the classifiers on the texts indicated above. Report the accuracy and generate a confusion matrix for each classifier. Experiment further, generating two additional classifiers. Can you improve the accuracy at all on the test set by, e.g., removing stop words, or re-sampling the training set to balance the classes ? Report the accuracy and generate a confusion matrix for the your modified classifiers. Ensure you program can be run, simply by invoking test (directory) where directory is the name of the directory holding the original text files. Your output should look something like the output shown on the next page (don't assume the numbers shown are reasonable Conrad 1 Dickens 3 0 1 Alcott Austen Alcott 372 1 Austen 4 235 Bronte 5 0 Conrad 4 1 Dickens 50 12 Multinomial=0.8994 Bronte 1 3 386 2 85 0 0 75 9 0 559 Alcott Alcott 369 Austen 1 Bronte 0 Conrad 1 Dickens 9 Bernoulli=0.9635 Austen 3 238 3 Bronte 2 1 386 0 14 Conrad 1 1 2 Dickens 3 2 0 1 3 12 7 673
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts