

Question: To speed-up floating-point programs, many architectures have Multiply Accumulate (MAC) instructions (A = A + B * C) that take advantage of optimized hardware and
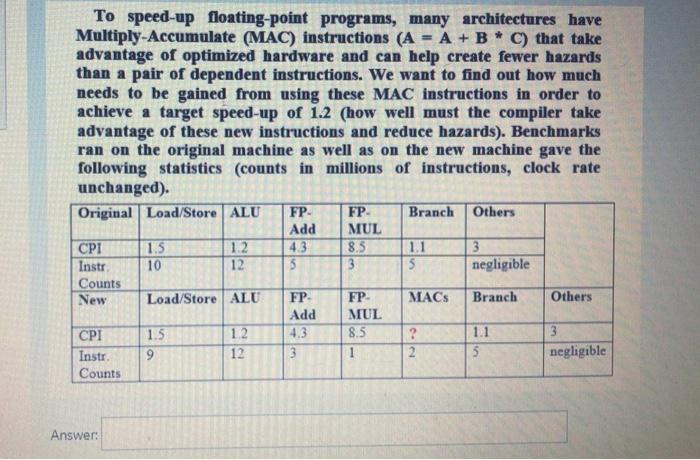
To speed-up floating-point programs, many architectures have Multiply Accumulate (MAC) instructions (A = A + B * C) that take advantage of optimized hardware and can help create fewer hazards than a pair of dependent instructions. We want to find out how much needs to be gained from using these MAC instructions in order to achieve a target speed-up of 1.2 (how well must the compiler take advantage of these new instructions and reduce hazards). Benchmarks ran on the original machine as well as on the new machine gave the following statistics (counts in millions of instructions, clock rate unchanged). Original Load/Store ALU FP- FP Branch Others Add MUL CPI 1.5 12 4.3 8.5 1.1 3 Instr 10 12 5 3 5 negligible Counts New Load/Store ALU FP FP MACS Branch Others Add MUL CPI 1.5 12 4.3 8.5 ? 1.1 3 Instr. 9 12 3 1 2 5 negligible Counts
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts