

Question: Use the read_csv function from pandas to read in the dataset from the file path and return the resulting dataframe. In [ ]: def
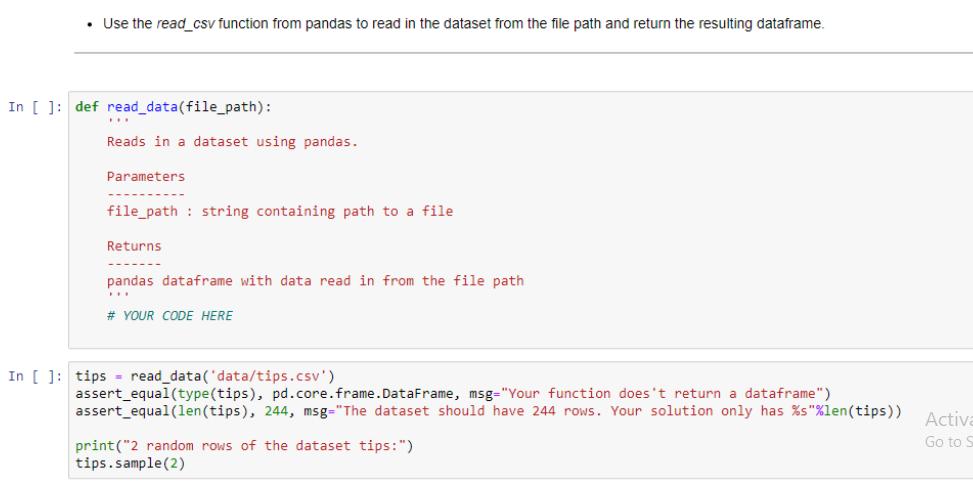
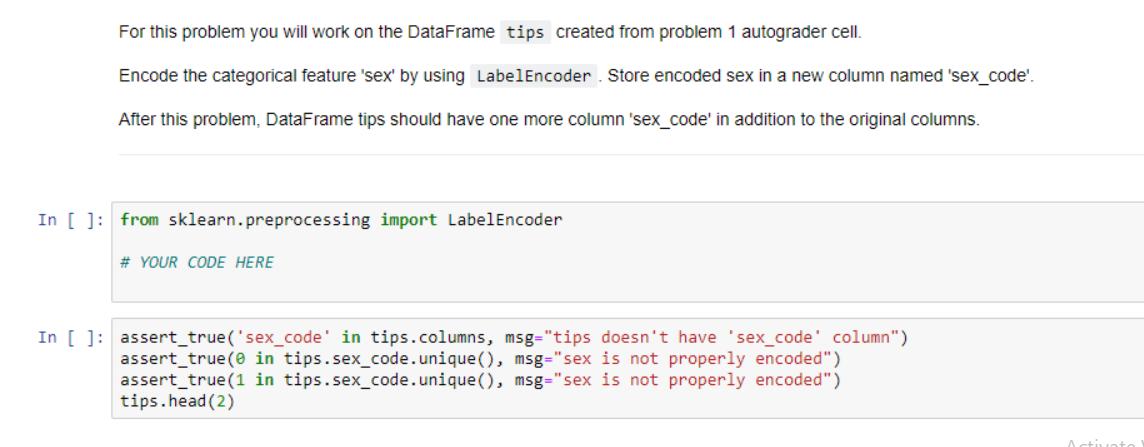
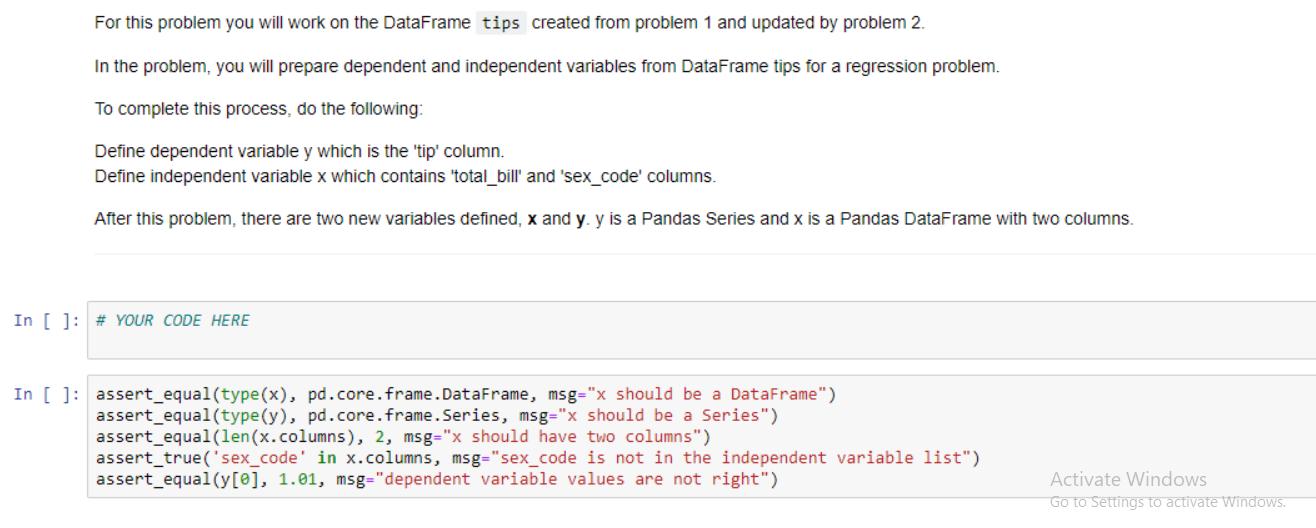
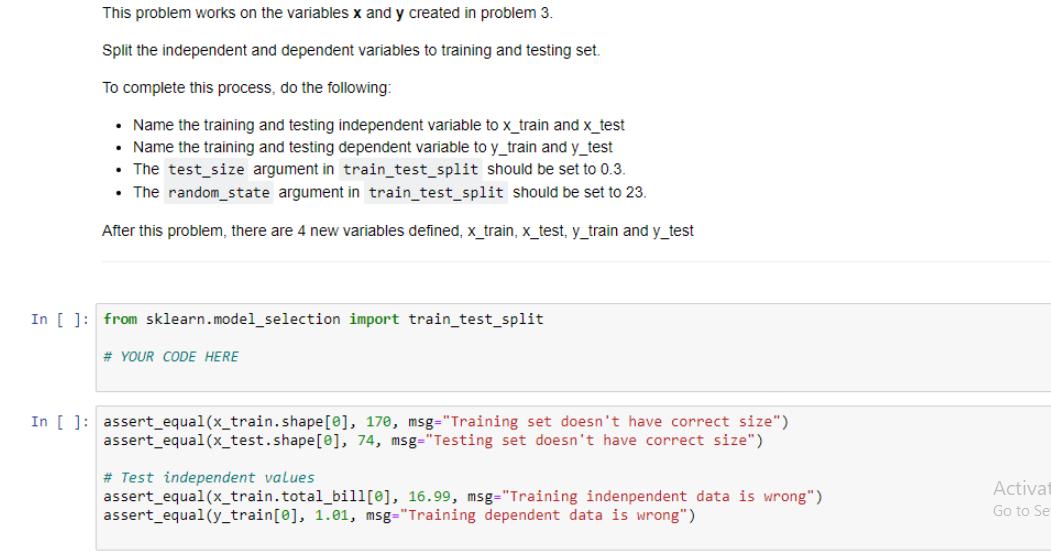
Use the read_csv function from pandas to read in the dataset from the file path and return the resulting dataframe. In [ ]: def read_data(file_path): ... Reads in a dataset using pandas. Parameters file_path string containing path to a file Returns. pandas dataframe with data read in from the file path # YOUR CODE HERE In [ ]: tips = read_data('data/tips.csv') assert_equal (type (tips), pd.core.frame.DataFrame, msg="Your function does't return a dataframe") assert_equal(len (tips), 244, msg="The dataset should have 244 rows. Your solution only has %s"%len(tips)) print("2 random rows of the dataset tips:") tips.sample (2) Activa Go to S For this problem you will work on the DataFrame tips created from problem 1 autograder cell. Encode the categorical feature 'sex' by using LabelEncoder. Store encoded sex in a new column named 'sex_code'. After this problem, DataFrame tips should have one more column 'sex_code' in addition to the original columns. In []: from sklearn.preprocessing import LabelEncoder # YOUR CODE HERE In [ ]: assert_true ('sex_code' in tips.columns, msg="tips doesn't have 'sex_code' column") assert true (0 in tips.sex_code.unique(), msg="sex is not properly encoded") assert true (1 in tips.sex_code.unique (), msg="sex is not properly encoded") tips.head (2) Activato! For this problem you will work on the DataFrame tips created from problem 1 and updated by problem 2. In the problem, you will prepare dependent and independent variables from DataFrame tips for a regression problem. To complete this process, do the following: Define dependent variable y which is the 'tip' column. Define independent variable x which contains 'total_bill' and 'sex_code' columns. After this problem, there are two new variables defined, x and y. y is a Pandas Series and x is a Pandas DataFrame with two columns. In [ ]: # YOUR CODE HERE In [ ]: assert_equal (type (x), pd.core.frame.DataFrame, msg="x should be a DataFrame") assert equal (type (y), pd.core.frame. Series, msg="x should be a Series") assert_equal(len (x.columns), 2, msg="x should have two columns") assert true('sex_code' in x.columns, msg="sex_code is not in the independent variable list") assert_equal (y [0], 1.01, msg="dependent variable values are not right") Activate Windows Go to Settings to activate Windows. This problem works on the variables x and y created in problem 3. Split the independent and dependent variables to training and testing set. To complete this process, do the following: Name the training and testing independent variable to x_train and x_test Name the training and testing dependent variable to y_train and y_test The test size argument in train_test_split should be set to 0.3. The random_state argument in train_test_split should be set to 23. After this problem, there are 4 new variables defined, x_train, x_test, y_train and y_test In []: from sklearn.model_selection import train_test_split # YOUR CODE HERE In [ ]: assert_equal(x_train.shape [0], 170, msg="Training set doesn't have correct size") assert_equal(x_test.shape [0], 74, msg="Testing set doesn't have correct size") # Test independent values assert_equal (x_train.total_bill[0], 16.99, msg="Training indenpendent data is wrong"). assert_equal (y_train [0], 1.01, msg="Training dependent data is wrong") Activat Go to Se
Step by Step Solution
3.44 Rating (138 Votes )
There are 3 Steps involved in it
Your code looks great It passes all of the assertions Here is a summary of your code PYTHON def read... View full answer

Get step-by-step solutions from verified subject matter experts