

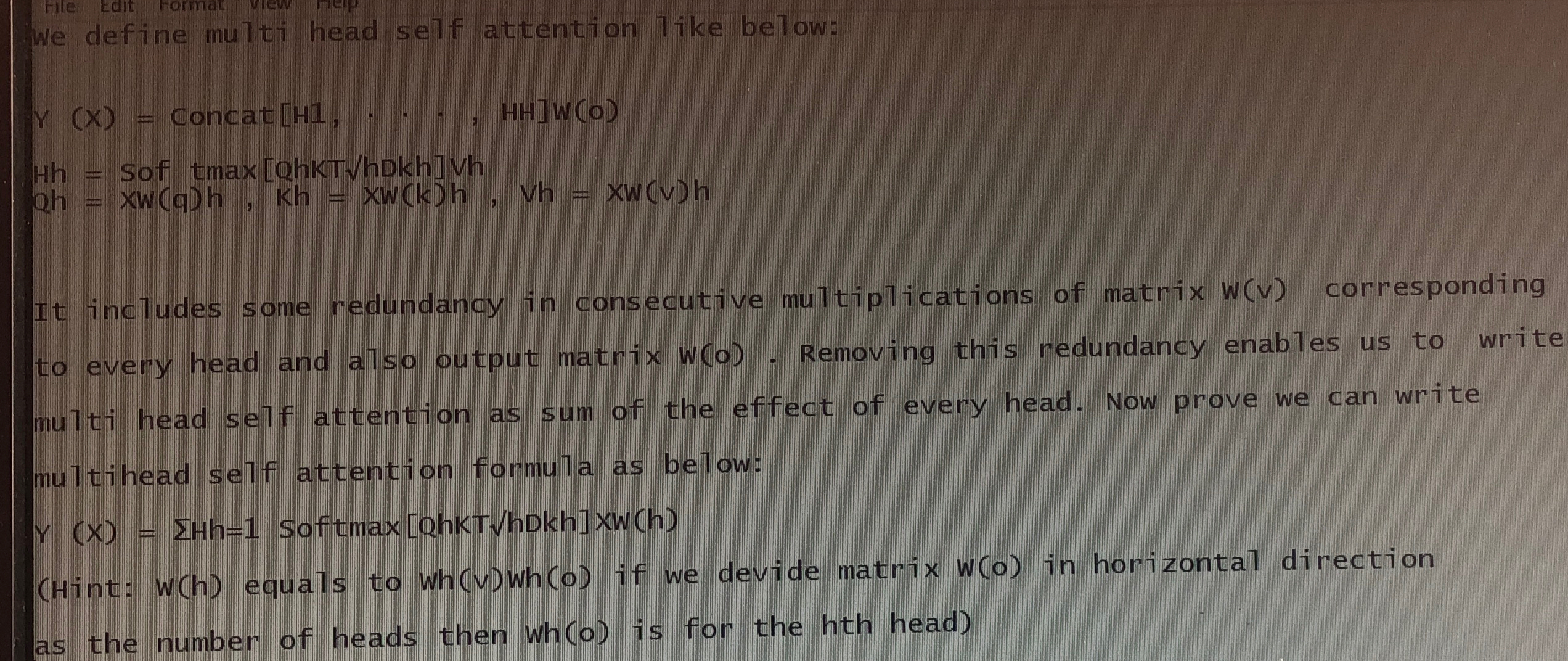
Question: We define multi head self attention l ke below: Y ( x ) = concat [ H 1 , dots, H H ] w (
We define multi head self attention lke below:
concat dots,
Softmax
It includes some redundancy in consecutive multiplications of matrix corresponding to every head and also output matrix Removing this redundancy enables us to write multi head self attention as sum of the effect of every head. Now prove we can write multihead self attention formula as below:
Softmax
Hint: equals to Who if we devide matrix in horizontal direction as the number of heads then who is for the hth head
Step by Step Solution
There are 3 Steps involved in it
1 Expert Approved Answer
Step: 1 Unlock

Question Has Been Solved by an Expert!
Get step-by-step solutions from verified subject matter experts
Step: 2 Unlock
Step: 3 Unlock