

Question: Write a C++ program to read records in a plain text file, then remove duplicated records, and write unique ones to a plain text file.
Write a C++ program to read records in a plain text file, then remove duplicated records, and write unique ones to a plain text file. You can use any algorithm and data structures that you prefer, as long as the results are correct. It is preferred, but not necessary, that your algorithm is as efficient as possible, both in processing time as well as memory management.
Input and Output Specification:
The input is one text file with 0 - 10000 records. The content of each record is confined to a pair of {} and doesnt contain { or }, but may have other symbols like space, comma, colon, single or double quote, and so on. In the input and output file, each line ends in a character. One record may not be necessary in one line in the input file. But you should output each unique record in one line without any spaces. The output records can be in any orders. It doesnt matter if you have or dont have one empty line at the end of the output file.
Example of input files (between the lines)
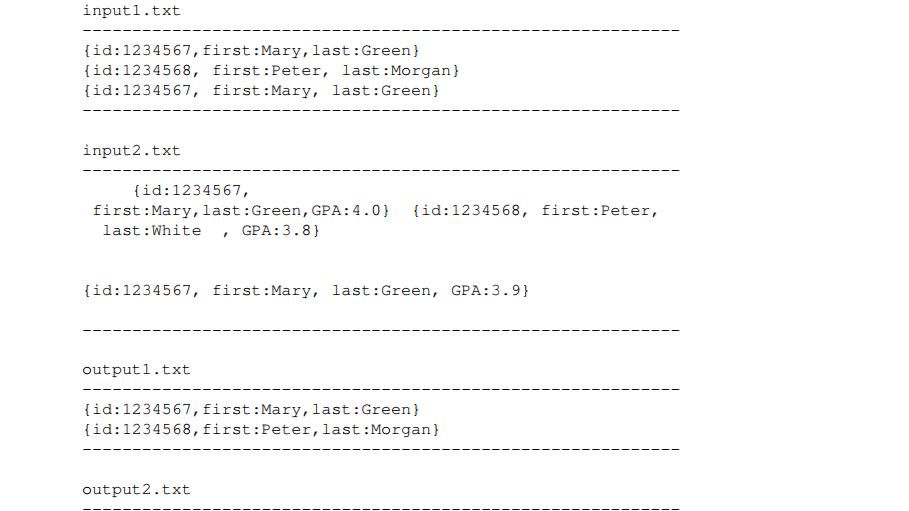

inputl.txt id: 1234567,first:Mary, last:Green) [id: 1234568, first:Peter, last :Morgan) id: 1234567, first : Mary, last:Green) input2.txt (id: 1234567, first:Mary, last:Green, GPA: 4.0 id: 1234568, first:Peter, last:White GPA:3.8) id: 1234567, first : Mary, last:Green, GPA:3.91 output1.txt id: 1234567,first:Mary, last:Green) fid: 1234568, first:Peter, last : Morgan) output2.txt
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts