

Question: Write a function that preprocesses the natural language data and returns the stems of the tokenized tweet. ( 1 5 % ) a . Remove
Write a function that preprocesses the natural language data and returns the stems of the tokenized tweet. a Remove the Twitter handles ie @userid in the column tweet b Remove punctuations, including ;:# c Remove numbers, ie d Remove special characters and nonEnglish characters e Remove words with length f Tokenize the comments g Apply stemming on the tokens and return the stems of the tokenized tweet. Code:
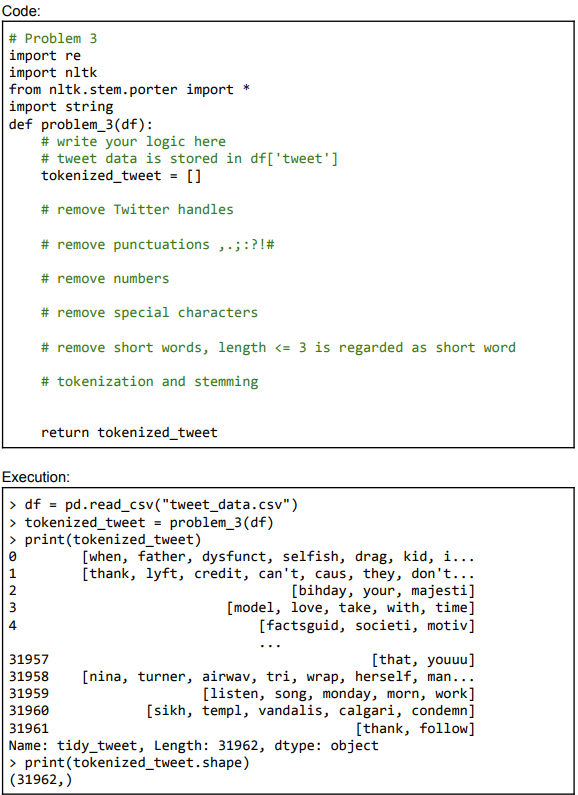
# Problem
import re
import nltk
from nltkstem.porter import
import string
def problemdf:
# write your logic here
# tweet data is stored in dftweet
tokenizedtweet
# remove Twitter handles
# remove punctuations ;:#
# remove numbers
# remove special characters
# remove short words, length is regarded as short word
# tokenization and stemming
return tokenizedtweet
Execution: square
df pdreadcsvtweetdata.csv
tokenizedtweet problemdf
printtokenizedtweet
when father, dysfunct, selfish, drag, kid, i
thank lyft credit, can't, caus, they, don't...
bihday your, majesti
model love, take, with, time
factsguid societi, motiv
that youuu
nina turner, airwav, tri, wrap, herself, man...
listen song, monday, morn, work
sikh templ, vandalis, calgari, condemn
thank follow
tidytweet, Length: dtype: object
Name: tingtokenizedtweet.shape
Step by Step Solution
There are 3 Steps involved in it
1 Expert Approved Answer
Step: 1 Unlock

Question Has Been Solved by an Expert!
Get step-by-step solutions from verified subject matter experts
Step: 2 Unlock
Step: 3 Unlock