

Question: Write a Java program to find frequent itemsets by implementing two efficient algorithms: A-Priori and PCY. The goal is to find frequent PAIRS of elements,
Write a Java program to find frequent itemsets by implementing two efficient algorithms: A-Priori and PCY. The goal is to find frequent PAIRS of elements, triples and larger are unecessary.
The retail dataset contains anonymized retail market basket data (88K baskets) from an anonymous retail store. The preprocessing step to map text labels into integers has already been done.

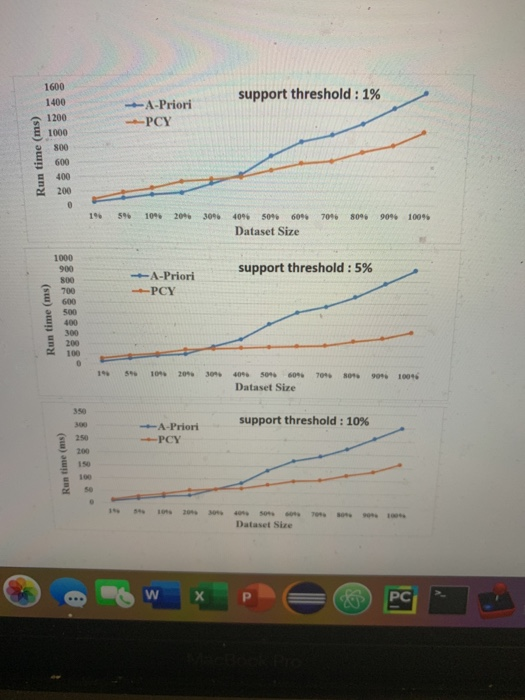
Project I (15%) Mining Frequent Itmsets Deadline: End of Friday February 14th 2020 Important Note: This project can be done in a group of two or individually. If you want to do. the project in a group of two, you have to send the name of your teammate to the instructor via email no later than end of Friday January 31", and otherwise it will be assumed that you perform the project individually. Description The main objective of this project is to find frequent itemsets by implementing two efficient algorithms: A-Priori and PCY. The goal is to find frequent pairs of elements. You do not need to find triples and larger itemsets. Resources Lectures 2 and 3 on Blackboard, and Chapter 6 of the textbook. Programming Language You can choose your favorite programming language, preferably one of the following ones: C, C+, Java, Ci, or Python. Dataset The retail dataset contains anonymized retail market basket data (88K baskets) from an anonymous retail store. The preprocessing step to map text labels into integers has already been done. Use Sublime Text, TextPad or Notepad++ or other software to open the file. Do not use Notepad. Dataset link: It is available on course page on Blackboard. Experiments Perform the scalability study for finding frequent pairs of elements by dividing the dataset into different chunks and measure the time performance. Provide the line chart. Provide results for the following support thresholds: 1%, 5%, 10%. For example, if your chunk is 10% of the dataset, you have around 8,800 baskets. Therefore, if your support threshold is 5%, you should count the pairs that appear in at least 440 baskets. See three samples below for three different support thresholds. Note: the sample charts contain hypothetical numbers! PC Book Pro 1600 support threshold : 1% A-Priori 1400 1200 -PCY 1000 800 600 400 200 10 30% 40 50 60 706 8096 90% 100% Dataset Size 1000 900 support threshold : 5% A-Priori 800 700 600 500 PCY 400 300 200 100 30 50 7016 90 1006 Dataset Size 350 support threshold : 10% A-Priori 300 250 PCY 200 150 100 50 20 Dataset Size PC Run time (ms) Run time (ms) Run time (ms) Project I (15%) Mining Frequent Itmsets Deadline: End of Friday February 14th 2020 Important Note: This project can be done in a group of two or individually. If you want to do. the project in a group of two, you have to send the name of your teammate to the instructor via email no later than end of Friday January 31", and otherwise it will be assumed that you perform the project individually. Description The main objective of this project is to find frequent itemsets by implementing two efficient algorithms: A-Priori and PCY. The goal is to find frequent pairs of elements. You do not need to find triples and larger itemsets. Resources Lectures 2 and 3 on Blackboard, and Chapter 6 of the textbook. Programming Language You can choose your favorite programming language, preferably one of the following ones: C, C+, Java, Ci, or Python. Dataset The retail dataset contains anonymized retail market basket data (88K baskets) from an anonymous retail store. The preprocessing step to map text labels into integers has already been done. Use Sublime Text, TextPad or Notepad++ or other software to open the file. Do not use Notepad. Dataset link: It is available on course page on Blackboard. Experiments Perform the scalability study for finding frequent pairs of elements by dividing the dataset into different chunks and measure the time performance. Provide the line chart. Provide results for the following support thresholds: 1%, 5%, 10%. For example, if your chunk is 10% of the dataset, you have around 8,800 baskets. Therefore, if your support threshold is 5%, you should count the pairs that appear in at least 440 baskets. See three samples below for three different support thresholds. Note: the sample charts contain hypothetical numbers! PC Book Pro 1600 support threshold : 1% A-Priori 1400 1200 -PCY 1000 800 600 400 200 10 30% 40 50 60 706 8096 90% 100% Dataset Size 1000 900 support threshold : 5% A-Priori 800 700 600 500 PCY 400 300 200 100 30 50 7016 90 1006 Dataset Size 350 support threshold : 10% A-Priori 300 250 PCY 200 150 100 50 20 Dataset Size PC Run time (ms) Run time (ms) Run time (ms)
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts