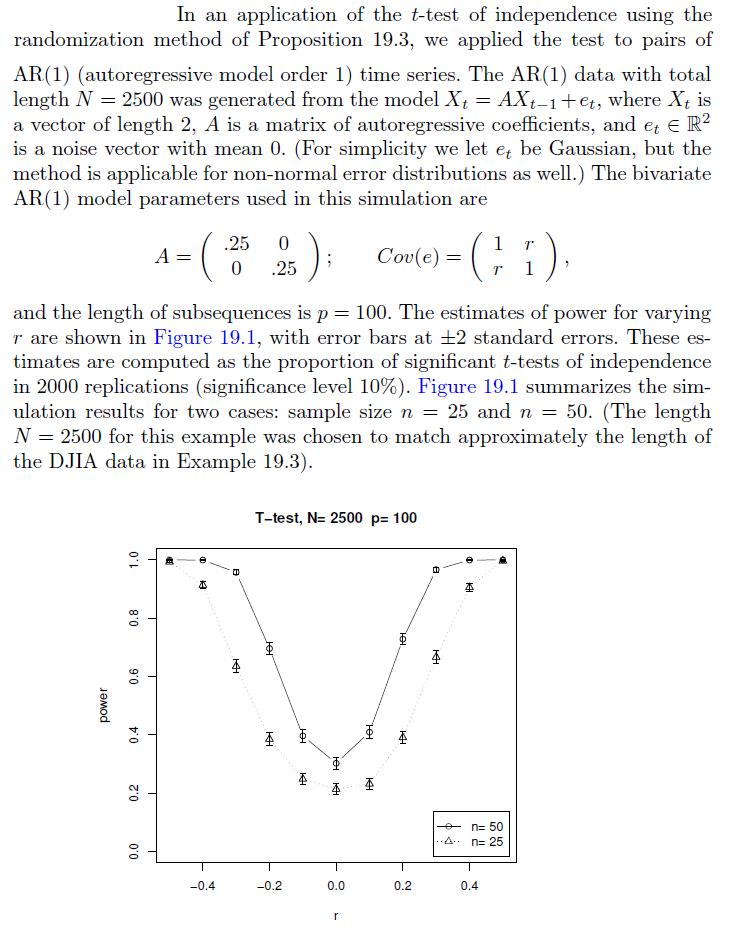
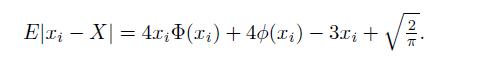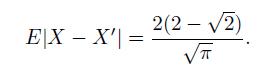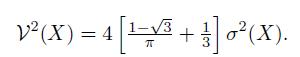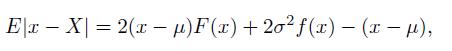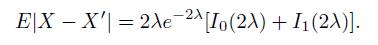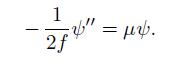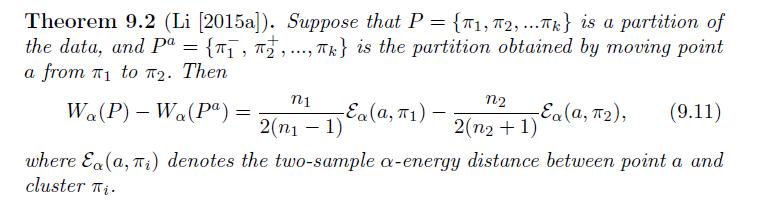Cases And Materials On Employment Law 8th Edition Richard Painter, Ann Holmes - Solutions
Discover comprehensive solutions for "Cases and Materials on Employment Law 8th Edition" by Richard Painter and Ann Holmes. Access the answers key and detailed solutions pdf for all chapters, providing step-by-step answers to solved problems. Enhance your understanding with our online solutions manual and instructor manual, designed to assist with textbook questions and answers. Our test bank offers chapter solutions and an array of questions and answers to aid your studies. Benefit from the free download of solutions, making it easier than ever to grasp complex employment law concepts.