

Question: Consider the following training/test split of the data. Construct a random forest regressor and identify the optimal subset size (m) in the sense of (R^{2})
Consider the following training/test split of the data. Construct a random forest regressor and identify the optimal subset size \(m\) in the sense of \(R^{2}\) score (see Remark \(8.3)\).
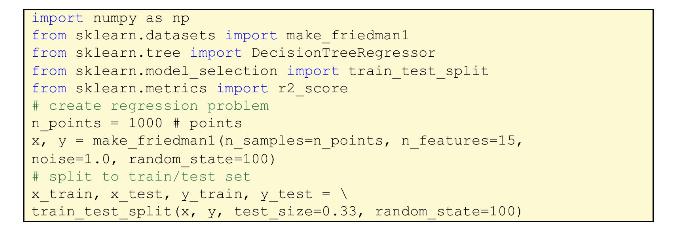
import numpy as np from sklearn.datasets import make friedmanl from sklearn.tree import DecisionTreeRegressor from sklearn.model_selection import train_test_split from sklearn.metrics import r2_score # create regression problem n_points 1000 points x, y = make_friedmanl (n_samples-n_points, n_features=15, noise 1.0, random_state=100) #split to train/test set. x_train, x_test, y_train, y_test = \ train_test_split(x, y, test_size=0.33, random_state=100)
Step by Step Solution
3.26 Rating (152 Votes )
There are 3 Steps involved in it
For our example ... View full answer

Get step-by-step solutions from verified subject matter experts