

Although request-level parallelism allows many machines to work on a single problem in parallel, thereby achieving greater
Question:
Although request-level parallelism allows many machines to work on a single problem in parallel, thereby achieving greater overall performance, one of the challenges is how to avoid dividing the problem too finely. If we look at this problem in the context of service level agreements (SLAs), using smaller problem sizes through greater partitioning can require increased effort to achieve the target SLA. Assume an SLA of 95% of queries respond at 0.5 s or faster, and a parallel architecture similar to MapReduce that can launch multiple redundant jobs to achieve the same result. For the following questions, assume the query–response time curve shown in Figure 6.36. The curve shows the latency of response, based on the number of queries per second, for a baseline server as well as a “small” server that uses a slower processor model.
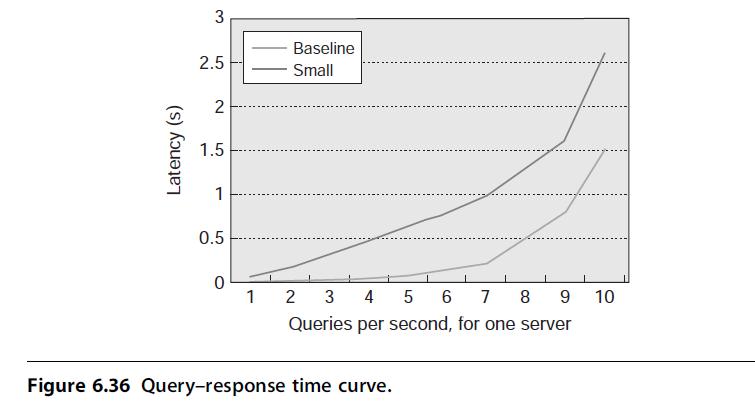
a. How many servers are required to achieve this SLA, assuming the query-response time curve shown in Figure 6.36 and the WSC receiving 30,000 queries per second? How many “small” servers are required to achieve this SLA, given this response-time probability curve? Looking only at server costs, how much cheaper must the “small” servers be than the normal servers to achieve a cost advantage for the target SLA?
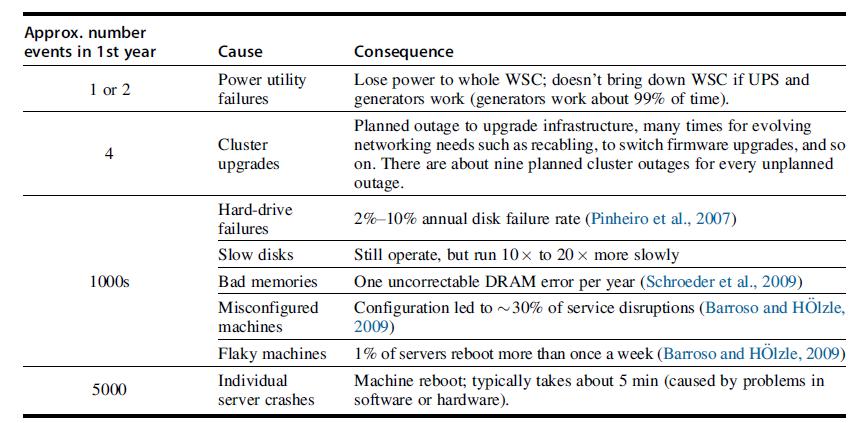
b. Often, “small” servers are also less reliable due to cheaper components. Using the numbers from Figure 6.1, assume that the number of events due to flaky machines and bad memories increases by 30%. How many “small” servers are required now? How much cheaper must those servers be than the standard servers?
c. Now assume a batch processing environment. The “small” servers provide 30% of the overall performance of the regular servers. Still assuming the reliability numbers from Exercise 6.15 part (b), how many “small” nodes are required to provide the same expected throughput of a 2400-node array of standard servers, assuming perfect linear scaling of performance to node size and an average task length of 10 min per node? What if the scaling is 85%? 60%?
d. Often the scaling is not a linear function, but instead a logarithmic function. A natural response may be instead to purchase larger nodes that have more computational power per node to minimize the array size. Discuss some of the trade-offs with this architecture.
Exercise 6.15
WSC programmers often use data replication to overcome failures in the software. Hadoop HDFS, for example, employs three-way replication (one local copy, one remote copy in the rack, and one remote copy in a separate rack), but it’s worth examining when such replication is needed.
a. Let us assume that Hadoop clusters are relatively small, with 10 nodes or less, and with dataset sizes of 10 TB or less. Using the failure frequency data in Figure 6.1, what kind of availability does a 10-node Hadoop cluster have with one-, two-, and three-way replications?
b. Assuming the failure data in Figure 6.1 and a 1000-node Hadoop cluster, what kind of availability does it have with one-, two-, and three-way replications? What can you reason about the benefits of replication, at scale?
Figure 6.1
Step by Step Answer:



Computer Architecture A Quantitative Approach
ISBN: 9780128119051
6th Edition
Authors: John L. Hennessy, David A. Patterson
