

Suppose that several secondary indexes exist on nonkey fields of a file, implemented using option 3 of
Question:
Suppose that several secondary indexes exist on nonkey fields of a file, implemented using option 3 of Section 17.1.3; for example, we could have secondary indexes on the fields Department_code, Job_code, and Salary of the EMPLOYEE file of Exercise 17.18. Describe an efficient way to search for and retrieve records satisfying a complex selection condition on these fields, such as (Department_code = 5 AND Job_code = 12 AND Salary = 50,000), using the record pointers in the indirection level.
Option 3 From Section 17.1.3:
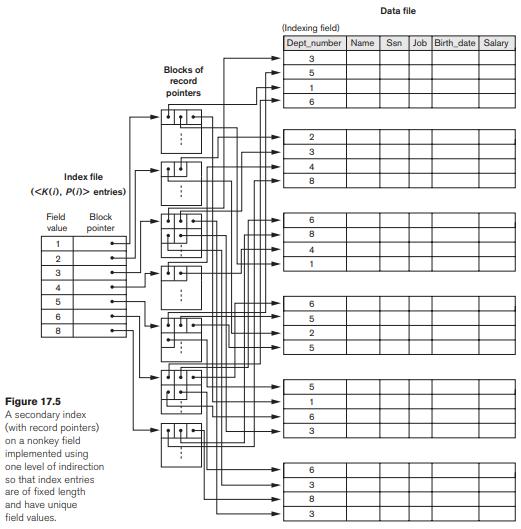
Which is more commonly used, is to keep the index entries themselves at a fixed length and have a single entry for each index field value, but to create an extra level of indirection to handle the multiple pointers. In this nondense scheme, the pointer P(i) in index entry <K(i), P(i)> points to a disk block, which contains a set of record pointers; each record pointer in that disk block points to one of the data file records with value K(i) for the indexing field. If some value K(i) occurs in too many records, so that their record pointers cannot fit in a single disk block, a cluster or linked list of blocks is used. This technique is illustrated in Figure 17.5. Retrieval via the index requires one or more additional block accesses because of the extra level, but the algorithms for searching the index and (more importantly) for inserting of new records in the data file are straightforward. The binary search algorithm is directly applicable to the index file since it is ordered. For range retrievals such as retrieving records where V1 ≤ K ≤ V2, block pointers may be used in the pool of pointers for each value instead of the record pointers. Then a union operation can be used on the pools of block pointers corresponding to the entries from V1 to V2 in the index to eliminate duplicates and the resulting blocks can be accessed. In addition, retrievals on complex selection conditions may be handled by referring to the record pointers from multiple non-key secondary indexes, without having to retrieve many unnecessary records from the data file.
Figure 17.5:
Exercise 17.18
Consider a disk with block size B = 512 bytes. A block pointer is P = 6 bytes long, and a record pointer is PR = 7 bytes long. A file has r = 30,000 EMPLOYEE records of fixed length. Each record has the following fields: Name (30 bytes), Ssn (9 bytes), Department_code (9 bytes), Address (40 bytes), Phone (10 bytes), Birth_date (8 bytes), Sex (1 byte), Job_code (4 bytes), and Salary (4 bytes, real number). An additional byte is used as a deletion marker.
a. Calculate the record size R in bytes.
b. Calculate the blocking factor bfr and the number of file blocks b, assuming an unspanned organization.
c. Suppose that the file is ordered by the key field Ssn and we want to construct a primary index on Ssn. Calculate
(i) The index blocking factor bfri (which is also the index fan-out fo);
(ii) The number of first-level index entries and the number of first-level index blocks;
(iii) The number of levels needed if we make it into a multilevel index;
(iv) The total number of blocks required by the multilevel index; and
(v) The number of block accesses needed to search for and retrieve a record from the file—given its Ssn value—using the primary index.
d. Suppose that the file is not ordered by the key field Ssn and we want to construct a secondary index on Ssn. Repeat the previous exercise (part c) for the secondary index and compare with the primary index.
e. Suppose that the file is not ordered by the nonkey field Department_code and we want to construct a secondary index on Department_code, using option 3 of Section 17.1.3, with an extra level of indirection that stores record pointers. Assume there are 1,000 distinct values of Department_code and that the EMPLOYEE records are evenly distributed among these values. Calculate
(i) The index blocking factor bfri (which is also the index fan-out fo);
(ii) The number of blocks needed by the level of indirection that stores record pointers;
(iii) The number of first-level index entries and the number of first-level index blocks;
(iv) The number of levels needed if we make it into a multilevel index;
(v) The total number of blocks required by the multilevel index and the blocks used in the extra level of indirection; and
(vi) The approximate number of block accesses needed to search for and retrieve all records in the file that have a specific Department_code value, using the index.
f. Suppose that the file is ordered by the nonkey field Department_code and we want to construct a clustering index on Department_code that uses block anchors (every new value of Department_code starts at the beginning of a new block). Assume there are 1,000 distinct values of Department_code and that the EMPLOYEE records are evenly distributed among these values. Calculate
(i) The index blocking factor bfri (which is also the index fan-out fo);
(ii) The number of first-level index entries and the number of first-level index blocks;
(iii) The number of levels needed if we make it into a multilevel index;
(iv) The total number of blocks required by the multilevel index; and
(v) The number of block accesses needed to search for and retrieve all records in the file that have a specific Department_code value, using the clustering index (assume that multiple blocks in a cluster are contiguous).
g. Suppose that the file is not ordered by the key field Ssn and we want to construct a B+-tree access structure (index) on Ssn. Calculate
(i) The orders p and pleaf of the B+-tree;
(ii) The number of leaf-level blocks needed if blocks are approximately 69% full (rounded up for convenience);
(iii) The number of levels needed if internal nodes are also 69% full (rounded up for convenience);
(iv) The total number of blocks required by the B+-tree; and
(v) The number of block accesses needed to search for and retrieve a record from the file—given its Ssn value—using the B+-tree.
h. Repeat part g, but for a B-tree rather than for a B+-tree. Compare your results for the B-tree and for the B+-tree.
Step by Step Answer:
To efficiently search for and retrieve records satisfying a complex selection condition on the secondary indexes Departmentcode Jobcode and Salary we can follow these steps 1 Perform index lookups on ...View the full answer



Fundamentals Of Database Systems
ISBN: 9780133970777
7th Edition
Authors: Ramez Elmasri, Shamkant Navathe
