

Question: 1. Import the necessary libraries. For this assignment, we'll need `numpy`, `matplotlib.pyplot`, and `pandas`. For some of the longer module names, remember we can alias
1. Import the necessary libraries. For this assignment, we'll need `numpy`, `matplotlib.pyplot`, and `pandas`. For some of the longer module names, remember we can alias them using `as` to make their types easier to work with.
2. Open and load the CSV file `Salary_Data.csv` into a Pandas dataframe. Name the dataframe variable something unique, like 'data' or 'df'. Remember that for CSV files, there's a built-in Pandas function for reading their data.
3. Use the dataframe you created to print the first 5 items (the 'head') to the output. Utilize Pandas' built-in functions for this!
4. Create scatter plot using the Pandas dataframe. Make the X-axis years of experience, and the Y-axis the corresponding salary. Output the result. If you've done everything up to this point correctly, it should look like the following image:

5. Implement the Least Squares approximation, to find a straight line that best approximates the data we've been provided with and plotted in the previous question. We'll be implementing this system manually - you're **not** allowed to use an external library like `numpy.linalg` to solve. You will, however, want to use the `numpy` constructions for numbers and matrices we already imported to manipulate your data.
> As a refresher, the Least Squares Approximation finds values $theta_0, theta_1$ such that $y = theta_0 + theta_1x$ is an accurate approximation of the trend of the data provided.
>
> In matrix form:
> $$A = [1 , X]$$
>
> $A$ can be thought of as a column of $1$'s and a column of sample $x$ values. Then, we define $theta$ as:
>
> $$theta = [theta_0, theta_1]^t$$
>
> So $b = A theta$
>
> To find the approximate result, we can use the pseudo-inverse of A:
$$theta = [(A^t A)^{(-1)} A^t] b$$
6. On top of the scatter plot you created in part **4**, we now want to use our calculated $theta$ to draw our approximate linear regression onto the plot surface. Start with the plot from earlier, and then use the `matplotlib.pyplot.plot` function to plot the predicted line from an array of $x_{pred}$ and $y_{pred}$ predictions. You'll need to likely compute $A$ for each section of the line in order to compute $y=A cdot theta$ for a given point - think about how you can use Numpy and matrices to calculate all of the points in the line at once!
If you've correctly set up your linear regression, as the end result you should see something that looks like this:

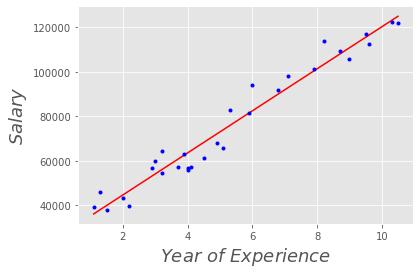
Csv file :- https://drive.google.com/file/d/1azUDkcZheHlu1nULJqnjyaC2UG--mtnM/view?usp=sharing
Salary 120000 100000 80000 60000 40000 - 2 6 YearsExperience 8 10
Step by Step Solution
3.41 Rating (170 Votes )
There are 3 Steps involved in it
Here is the Python code to perform linear regression on the salary data PYTHON import numpy as np im... View full answer

Get step-by-step solutions from verified subject matter experts