

Question: 1) Language L is represented by the regular expression (a(ac)*) + (a(ca)*) a. Convert this regular expression into the NFA M with ^-moves that
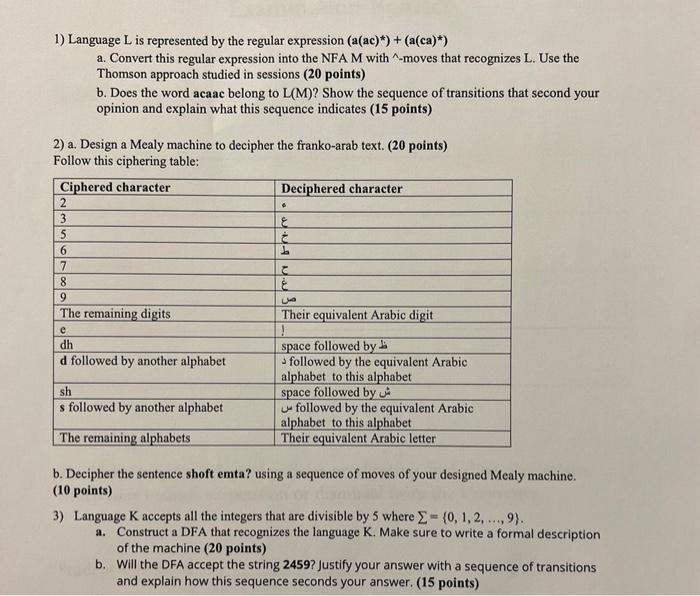
1) Language L is represented by the regular expression (a(ac)*) + (a(ca)*) a. Convert this regular expression into the NFA M with ^-moves that recognizes L. Use the Thomson approach studied in sessions (20 points) 2) a. Design a Mealy machine to decipher the franko-arab text. (20 points) Follow this ciphering table: Ciphered character 2 b. Does the word acaac belong to L(M)? Show the sequence of transitions that second your opinion and explain what this sequence indicates (15 points) 3 5 6 7 8 9 The remaining digits e dh d followed by another alphabet sh s followed by another alphabet The remaining alphabets Deciphered character $ E b E & Their equivalent Arabic digit space followed by a followed by the equivalent Arabic alphabet to this alphabet space followed by followed by the equivalent Arabic alphabet to this alphabet Their equivalent Arabic letter b. Decipher the sentence shoft emta? using a sequence of moves of your designed Mealy machine. (10 points) 3) Language K accepts all the integers that are divisible by 5 where = {0, 1, 2, ..., 9). a. Construct a DFA that recognizes the language K. Make sure to write a formal description of the machine (20 points) b. Will the DFA accept the string 2459? Justify your answer with a sequence of transitions and explain how this sequence seconds your answer. (15 points)
Step by Step Solution
3.29 Rating (155 Votes )
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts