

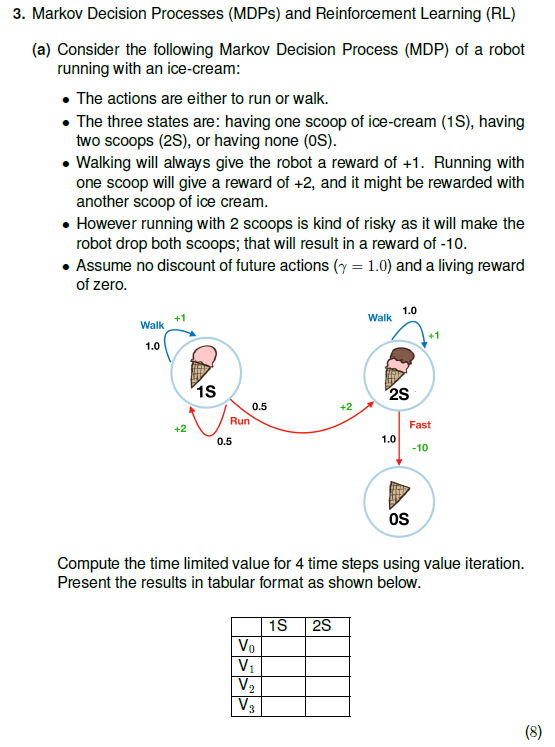
Question: 3. Markov Decision Processes (MDPs) and Reinforcement Learning (RL) (a) Consider the following Markov Decision Process (MDP) of a robot running with an ice-cream: .
Step by Step Solution
There are 3 Steps involved in it
1 Expert Approved Answer
Step: 1 Unlock

Question Has Been Solved by an Expert!
Get step-by-step solutions from verified subject matter experts
Step: 2 Unlock
Step: 3 Unlock