

Question: 5.1) (10 points) Consider a logistic regression model to classify a document into two classes: postive class (sports), negative class (not sports). The model is

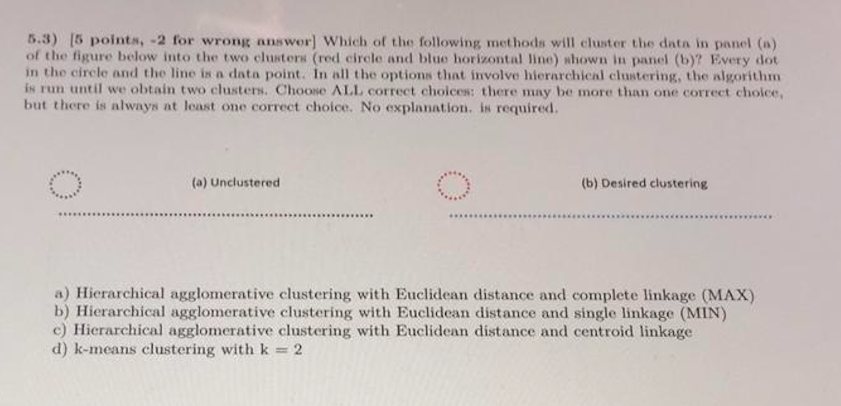
5.1) (10 points) Consider a logistic regression model to classify a document into two classes: postive class (sports), negative class (not sports). The model is trained and the weights are wi-In(), w - In(2) and w - In(3) with a bias term uo = 0. A given document has feature vector i = 1, 21, and = 1. Based on this logistic regression model, what is the probability that this document is about sports? Please provide your answer in the form of a fraction, you do not need a calculator for this question, logs for the weights just to make the math easier. 5.2) (11 points) For this question, you are interested in modelling customer response to food deals offered by different restaurants. The data shown in the table below lists 10 data points: the training data with labels. The first column in the table lists the deal id. The second column indicates the label, whether the user got the deal and ordered the food or not. The remaining three attributes describe the deals: Price Category specifies where the price level of the deal, Food type indicates whether the deal is on is Pizan or on Pide, Delivery speed indicates whether the restaurant's delivery speed is Fast or Slow. You will try to determine whether the customer will get the deal based on the attributes of the food heal (Price Category, Food type, Delivery Speed) by building a decision tree classifier. Deal id Ordered (Y) Price Category (X1) Food Type(X2) Delivery Speed(X) 1 No High Pide Slow 2 Yes Low Pizza Fast 3 No High Pizza Slow 4 No Medium Pide Fast 5 Yes Low Pizza Slow 6 No High Pide Slow 7 Yes Low Pide Slow 8 Yes Medium Pizza Fast 9 Yes Medium Pizza Fast 10 No Medium Pide Fast Table 1: Deal order data, 5.2a) (4 pts. What is the initial entropy of Ordered based on the training data? Show your work. 5.2b) [7 pts.) Assume that Price Category is chosen for the root of the decision tree. What is the information gain associated with this attribute? 5.3) (5 points, -2 for wrong answor] Which of the following methods will cluster the data in panel (*) of the figure below into the two clusters (red circle and blue horizontal line) shown in panel (b)? Every dot in the circle and the line is a data point. In all the options that involve hierarchical clustering, the algorithm is run until we obtain two clusters. Choose ALL correct choices: there may be more than one correct choice, but there is alwnys at least one correct choice. No explanation is required. (a) Unclustered (b) Desired clustering ************************************ ******** a) Hierarchical agglomerative clustering with Euclidean distance and complete linkage (MAX) b) Hierarchical agglomerative clustering with Euclidean distance and single linkage (MIN) c) Hierarchical agglomerative clustering with Euclidean distance and centroid linkage d) k-means clustering with k = 2
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts