

Question: a. (10) Which operation(s) in the loop can NOT be parallelized? Hint: these will be the operation(s) that depend on the result of that operation

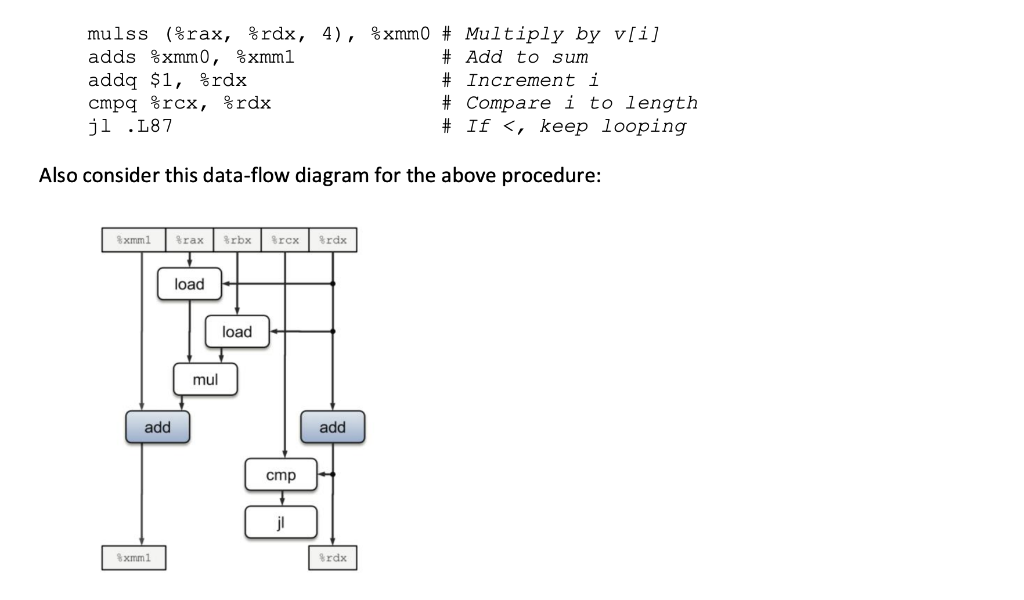

a. (10) Which operation(s) in the loop can NOT be parallelized? Hint: these will be the operation(s) that depend on the result of that operation from the previous loop iteration. Hint: see discussion around Figures 5.14 and 5.15. Write your answers in your solutions document.
b. (10) Given your answer from part a, what is the best-case CPE for the loop as currently written? Assume that float addition has a latency of 3 cycles, float multiplication has a latency of 5 cycles, and all integer operations have a latency of 1 cycle. Hint: the best-case CPE will be latency of the slowest of the operation(s) you identified in part a. Write your answers in your solutions document.
c. (10) Implement a procedure inner2 that is functionally equivalent to inner but uses four-way loop unrolling with four parallel accumulators. Hint: see Figure 5.21. Also implement an int main() function to test your procedure. Name your source file 6-2c.c.
d. (10) Using your code from part c, collect data on the execution times of inner and inner2 with varying array lengths. Summarize your findings and argue whether inner or inner2 is more efficient than the other (or not). Create a graph using appropriate data points to support your argument. Include your summary and graph in your solutions document. Compile with -Og.
2. [40] Suppose we've got a procedure that computes the inner product of two arrays u and v. Consider the following C code: = void inner (float *u, float *v, int length, float *dest) { int i; float sum 0.0f; for (i 0; i
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts