

Question: Can I get python code that runs in jupyter notebook from the above images. import requests import re US-STOPWORDS= [a, about, above, above, across, after,
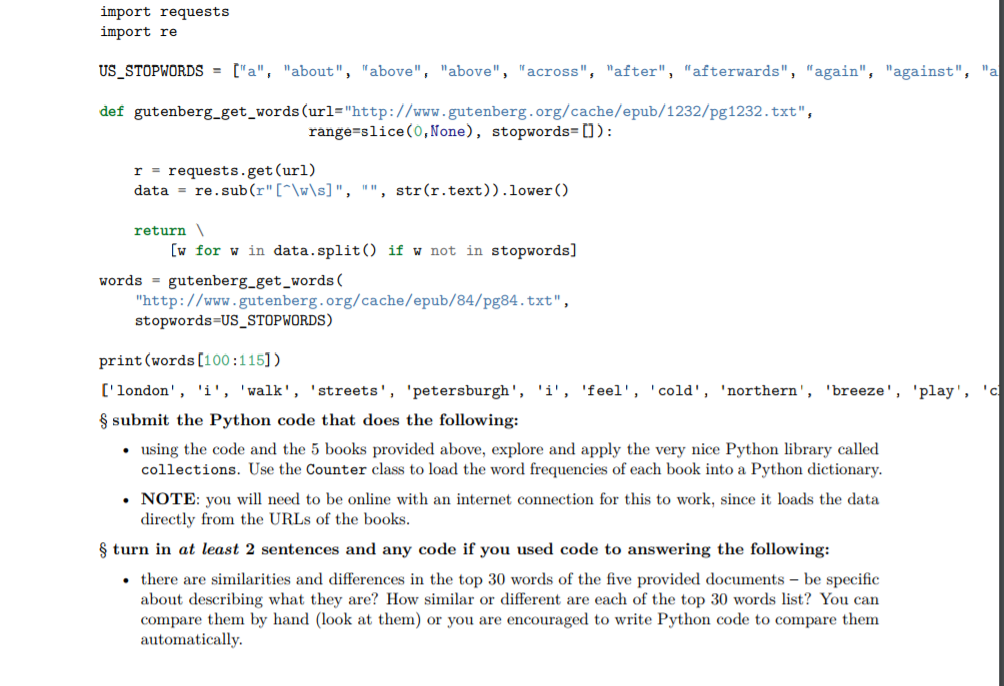

Can I get python code that runs in jupyter notebook from the above images.
import requests import re US-STOPWORDS= ["a", "about", "above", "above", "across", "after", "afterwards", "again", def gutenberg-get-words (url="http://www.gutenberg.org/cache/epub/1232/pg1232.txt", "against", "a range-slice (0, None), stopwords-0) r = requests.get(ur1) data = re.sub(r"[^\w\s]", "", str (r.text)).lower() return w for w in data.split) if w not in stopwords gutenberg-get-words( words = http://www.gutenberg.org/cache/epub/84/pg84.txt", stopwords-US_STOPWORDS) print(words [100:115]) ['london', 'i', 'valk', 'streets', 'petersburgh', 'i', 'feel', 'cold', 'northern', 'breeze', 'play', 'c submit the Python code that does the following: using the code and the 5 books provided above, explore and apply the very nice Python library called collections. Use the Counter class to load the word frequencies of each book into a Python dictionary. NOTE: you need to be online with an internet connection for this to work, since it loads the data directly from the URLs of the books turn in at least 2 sentences and any code if you used code to answering the following: there are similarities and differences in the top 30 words of the five provided documents -be specific about describing what they are? How similar or different are each of the top 30 words list? You can compare them by hand (look at them) or you are encouraged to write Python code to compare them automatically
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts