

Question: Consider a neural net with one hidden layer, two inputs a and b, one hidden unit c, and one output unit d. The activation function
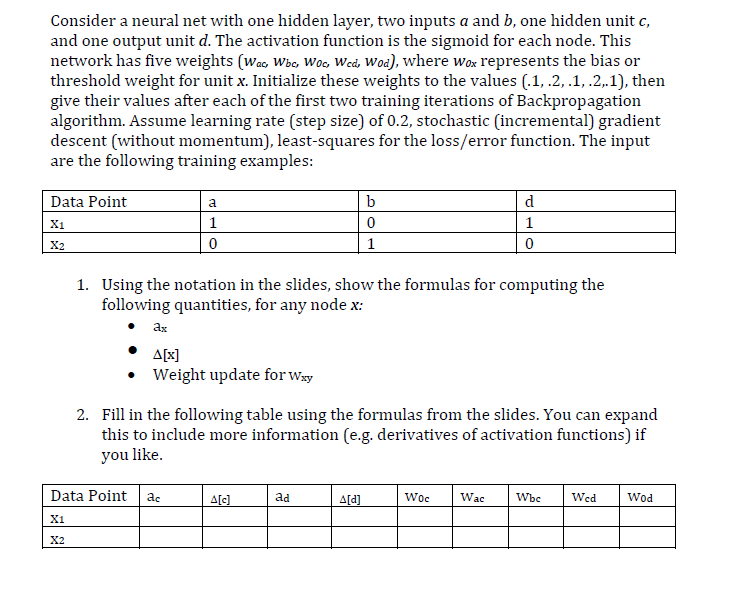
Consider a neural net with one hidden layer, two inputs a and b, one hidden unit c, and one output unit d. The activation function is the sigmoid for each node. This network has five weights (Wac, Wbe, Woc, Wed, Wod), where wox represents the bias or threshold weight for unit x. Initialize these weights to the values (.1,.2,.1,.2.1), then give their values after each of the first two training iterations of Backpropagation algorithm. Assume learning rate (step size) of 0.2, stochastic (incremental) gradient descent (without momentum), least-squares for the loss/error function. The input are the following training examples: Data Point Xi a 1 0 b 0 1 d 1 0 1. Using the notation in the slides, show the formulas for computing the following quantities, for any node x: ax A[x] Weight update for Wxy 2. Fill in the following table using the formulas from the slides. You can expand this to include more information (e.g. derivatives of activation functions) if you like. Data Point ac A[c] ad A[a] Woc Wac Wbc Wed Wod Xi X2 Consider a neural net with one hidden layer, two inputs a and b, one hidden unit c, and one output unit d. The activation function is the sigmoid for each node. This network has five weights (Wac, Wbe, Woc, Wed, Wod), where wox represents the bias or threshold weight for unit x. Initialize these weights to the values (.1,.2,.1,.2.1), then give their values after each of the first two training iterations of Backpropagation algorithm. Assume learning rate (step size) of 0.2, stochastic (incremental) gradient descent (without momentum), least-squares for the loss/error function. The input are the following training examples: Data Point Xi a 1 0 b 0 1 d 1 0 1. Using the notation in the slides, show the formulas for computing the following quantities, for any node x: ax A[x] Weight update for Wxy 2. Fill in the following table using the formulas from the slides. You can expand this to include more information (e.g. derivatives of activation functions) if you like. Data Point ac A[c] ad A[a] Woc Wac Wbc Wed Wod Xi X2
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts