

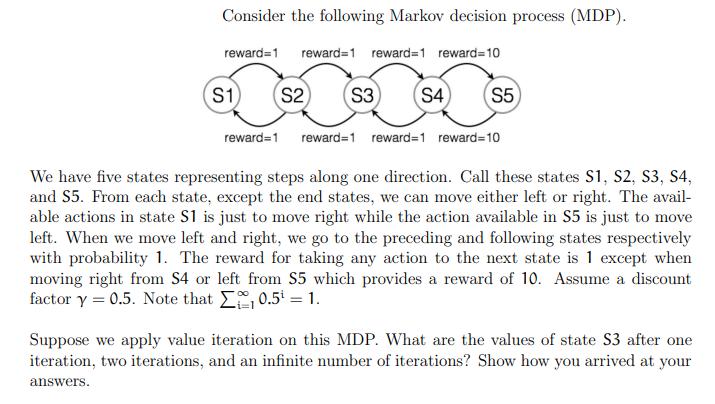
Consider the following Markov decision process (MDP). reward 1 reward=1 reward=1 reward=10 S1 S2 (S3) S4...
Fantastic news! We've Found the answer you've been seeking!
Question:
Expert Answer:

Related Book For 

Artificial Intelligence Structures And Strategies For Complex Problem Solving
ISBN: 9780321545893
6th Edition
Authors: George Luger
Posted Date:
