

Question: Course: Machine Learning def get_embedding_vectors (tokenizer, dim=300): embedding_index = {} with open('glove. 348.3000.txt', 'r', encoding=cp437, errors='ignore') as f: for line in tqdm.tqdm(f, Reading fasttext): values
Course: Machine Learning
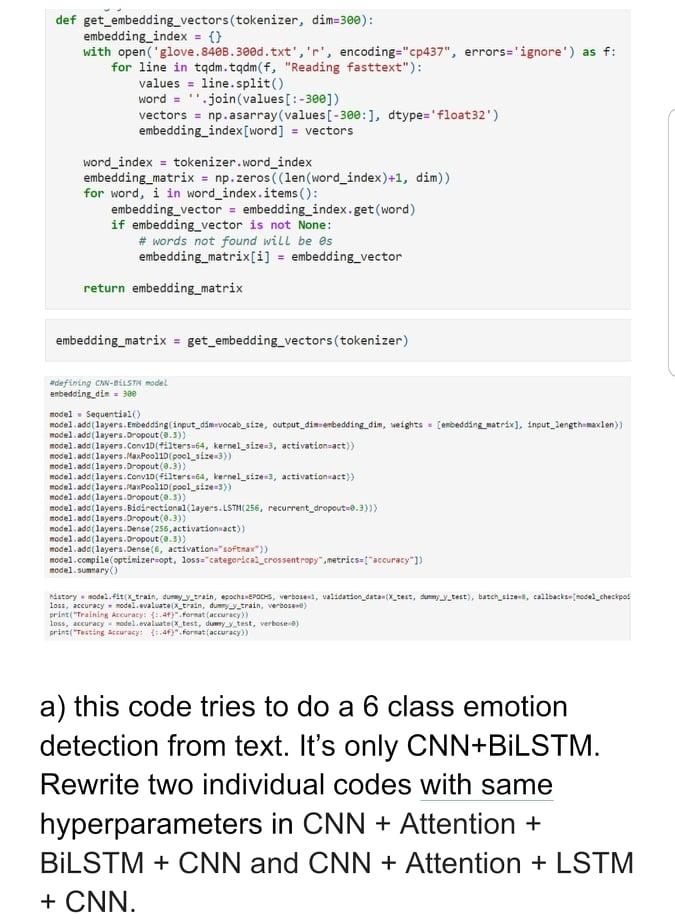
def get_embedding_vectors (tokenizer, dim=300): embedding_index = {} with open('glove. 348.3000.txt', 'r', encoding="cp437", errors='ignore') as f: for line in tqdm.tqdm(f, "Reading fasttext"): values = line.split() word = ".join(values[:-300]) vectors = np.asarray(values [-300 :], dtype='float32) embedding_index [word] = vectors word_index = tokenizer.word_index embedding_matrix = np.zeros((len (word_index)+1, dim)) for word, i in word_index.items(): embedding_vector = embedding_index.get(word) if embedding_vector is not None: # words not found will be es embedding_matrix[i] = embedding_vector return embedding_matrix = embedding_matrix = get_embedding_vectors (tokenizer) #defining with model enbedding_din model. Sequential() model ade(layers Enoadding(input_dimivocab_size, output_din-erbedding_din, weights enbedding_matrix], input_2ength maxlen) model.add(layers. Dropout(0.3) model.ado(layers.Convibetilters=64, kernel_size=3, activation-act)) model.add(layers.MaxPool1D(pool_size=3>) model.add(layers.Dropout(0.3) model ade(layers.Convid(+1tarteta, kernel_size, activation act)) model.add(layers.PaxPoolid (pool_size-3)) model.add(layers.Dropout(0.3)) model.add(layers. Bidirectional(Layers. ESTH(256, recurrent_dropout=0.3}}) model.add(layers. Dropout(0.3)) model.ado(layers, Dense(255, activation act)) model.add(layers. Dropout(0.5)) model.add(layers.Dense, activation='softmax")) modal.compile optimizer-opt, loss="categorical_crossentropy".metritsst" accuracy")) model sumiary() nestory.model.f.tx_train, dummy tean, erachotes, verbouw, validation_data tx_tes, mm_9_test), batch_ze, callbacksedel_checkpot loss, accuracy - model evaluate Ix_tran, drain, verbos) print("Training Accuracy: +4+) Format (accuracy) loss, accuracy model evaluatex test, dumy_test, verbosea) print("Testing accuracy: 7:46) Format accuracy)) a) this code tries to do a 6 class emotion detection from text. It's only CNN+BILSTM. Rewrite two individual codes with same hyperparameters in CNN + Attention + BILSTM + CNN and CNN + Attention + LSTM + CNN. def get_embedding_vectors (tokenizer, dim=300): embedding_index = {} with open('glove. 348.3000.txt', 'r', encoding="cp437", errors='ignore') as f: for line in tqdm.tqdm(f, "Reading fasttext"): values = line.split() word = ".join(values[:-300]) vectors = np.asarray(values [-300 :], dtype='float32) embedding_index [word] = vectors word_index = tokenizer.word_index embedding_matrix = np.zeros((len (word_index)+1, dim)) for word, i in word_index.items(): embedding_vector = embedding_index.get(word) if embedding_vector is not None: # words not found will be es embedding_matrix[i] = embedding_vector return embedding_matrix = embedding_matrix = get_embedding_vectors (tokenizer) #defining with model enbedding_din model. Sequential() model ade(layers Enoadding(input_dimivocab_size, output_din-erbedding_din, weights enbedding_matrix], input_2ength maxlen) model.add(layers. Dropout(0.3) model.ado(layers.Convibetilters=64, kernel_size=3, activation-act)) model.add(layers.MaxPool1D(pool_size=3>) model.add(layers.Dropout(0.3) model ade(layers.Convid(+1tarteta, kernel_size, activation act)) model.add(layers.PaxPoolid (pool_size-3)) model.add(layers.Dropout(0.3)) model.add(layers. Bidirectional(Layers. ESTH(256, recurrent_dropout=0.3}}) model.add(layers. Dropout(0.3)) model.ado(layers, Dense(255, activation act)) model.add(layers. Dropout(0.5)) model.add(layers.Dense, activation='softmax")) modal.compile optimizer-opt, loss="categorical_crossentropy".metritsst" accuracy")) model sumiary() nestory.model.f.tx_train, dummy tean, erachotes, verbouw, validation_data tx_tes, mm_9_test), batch_ze, callbacksedel_checkpot loss, accuracy - model evaluate Ix_tran, drain, verbos) print("Training Accuracy: +4+) Format (accuracy) loss, accuracy model evaluatex test, dumy_test, verbosea) print("Testing accuracy: 7:46) Format accuracy)) a) this code tries to do a 6 class emotion detection from text. It's only CNN+BILSTM. Rewrite two individual codes with same hyperparameters in CNN + Attention + BILSTM + CNN and CNN + Attention + LSTM + CNN
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts