

Question: defgodon.usagelsegi # Given a DNA sequence in string object, this function will return a dictionary that have all # codons existing in this sequence and

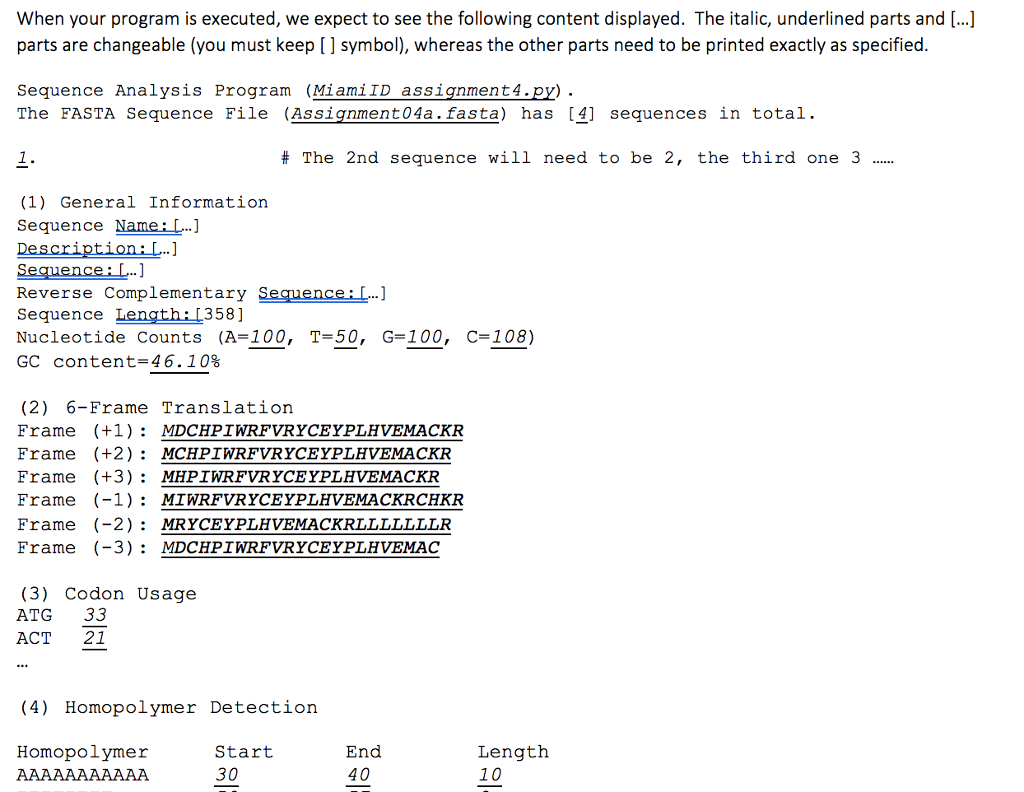
defgodon.usagelsegi # Given a DNA sequence in string object, this function will return a dictionary that have all # codons existing in this sequence and the relevant frequency counts. You can utilize the tt last function that you coded for assignment No.2 and do some modifications codon dicte return codon. dict When your program is executed, we expect to see the following content displayed. The italic, underlined parts and [...] parts are changeable (you must keep [ ] symbol), whereas the other parts need to be printed exactly as specified Sequence Analysis Program (MiamiID assignment 4.py) The FASTA Seguence File (Assignment04a. fasta) has [41 sequences in total. # The 2nd sequence will need to be 2, the third one 3 (1) General Information Sequence Name... Reverse Complementary Sequence:L Sequence Length: 1358] Nucleotide Counts (A-100, T=50, GC content=46.10% ] G-100, C-108) (2) 6-Frame Translation Frame (+1MDCHPIWRFVRYCEYPLHVEMACKR Frame (+2): MCHPIWRFVRYCEYPLHVEMACKR Frame (+3)MHPIWRFVRYCEYPLHVEMACKR Frame (-1) MIWRFVRYCEYPLHVEMACKRCHKR Frame (-2) : MRYCEYPLHVEMACKRLLLLLLLR Frame (-3)MDCHPIWRFVRYCEYPLHVEMAC (3) Codon Usage ATG 33 ACT 21 (4) Homopolymer Detection Homopolymer Start 30 End 40 Length 10 defgodon.usagelsegi # Given a DNA sequence in string object, this function will return a dictionary that have all # codons existing in this sequence and the relevant frequency counts. You can utilize the tt last function that you coded for assignment No.2 and do some modifications codon dicte return codon. dict When your program is executed, we expect to see the following content displayed. The italic, underlined parts and [...] parts are changeable (you must keep [ ] symbol), whereas the other parts need to be printed exactly as specified Sequence Analysis Program (MiamiID assignment 4.py) The FASTA Seguence File (Assignment04a. fasta) has [41 sequences in total. # The 2nd sequence will need to be 2, the third one 3 (1) General Information Sequence Name... Reverse Complementary Sequence:L Sequence Length: 1358] Nucleotide Counts (A-100, T=50, GC content=46.10% ] G-100, C-108) (2) 6-Frame Translation Frame (+1MDCHPIWRFVRYCEYPLHVEMACKR Frame (+2): MCHPIWRFVRYCEYPLHVEMACKR Frame (+3)MHPIWRFVRYCEYPLHVEMACKR Frame (-1) MIWRFVRYCEYPLHVEMACKRCHKR Frame (-2) : MRYCEYPLHVEMACKRLLLLLLLR Frame (-3)MDCHPIWRFVRYCEYPLHVEMAC (3) Codon Usage ATG 33 ACT 21 (4) Homopolymer Detection Homopolymer Start 30 End 40 Length 10
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts