

Question: # Description: This script performs sentiment analysis on the Amazon product reviews dataset using spaCy and TextBlob. # Load spaCy model import spacy from spacytextblob.spacytextblob
# Description: This script performs sentiment analysis on the Amazon product reviews dataset using spaCy and TextBlob.
# Load spaCy model
import spacy
from spacytextblob.spacytextblob import SpacyTextBlob
nlp spacy.loadencorewebsm
nlpaddpipespacytextblob
import numpy as np
import pandas as pd
dataframepdreadcsvrC:UsersUserOneDriveDesktopcsv
dataframe.head
Preprocessing the text data"""
# Select 'review.text' column
reviewsdata dataframereviewstext'
# Remove missing values
cleandata dataframe.dropnasubsetreviewstext'
# Function to apply preprocessing to the 'reviews.text' column using loc
def preprocesstexttext:
# Use spaCy to tokenize and remove stopwords
doc nlptext
tokens tokentext.lowerstrip for token in doc if not token.isstop
return jointokens
nlp spacy.loadencorewebsm
dataframereviewstext' dataframereviewstext'applypreprocesstext
# Function for sentiment analysis
def analyzesentimentreview:
# Process the review using spaCy
doc nlpreview
# Get sentiment using the sentiment attribute
sentiment doc.sentiment
# Determine sentiment category positive negative, or neutral
if sentiment :
return 'Positive'
elif sentiment :
return 'Negative'
else:
return 'Neutral'
# Text usage
samplereview "I love this product. It's amazing!"
sentimentresult analyzesentimentsamplereview
printfSentiment: sentimentresult
# Test the model for Sample Model Reviews
# Example usage of the sentiment analysis function
def testsentimentanalysisreview:
sentimentresult analyzesentimentreview
printfReview: review
printfSentiment: sentimentresult
print
# Choose two reviews for testing make sure the indices are valid
reviewindex
reviewindex
# Retrieve the reviews using indexing
review dataframereviewstext'reviewindex
review dataframereviewstext'reviewindex
# Test the sentiment analysis function on the selected reviews
testsentimentanalysisreview
testsentimentanalysisreview
# Compare the similarity of the two reviews using spaCy similarity
similarityscore nlpreviewsimilaritynlpreview
printfSimilarity Score: similarityscore
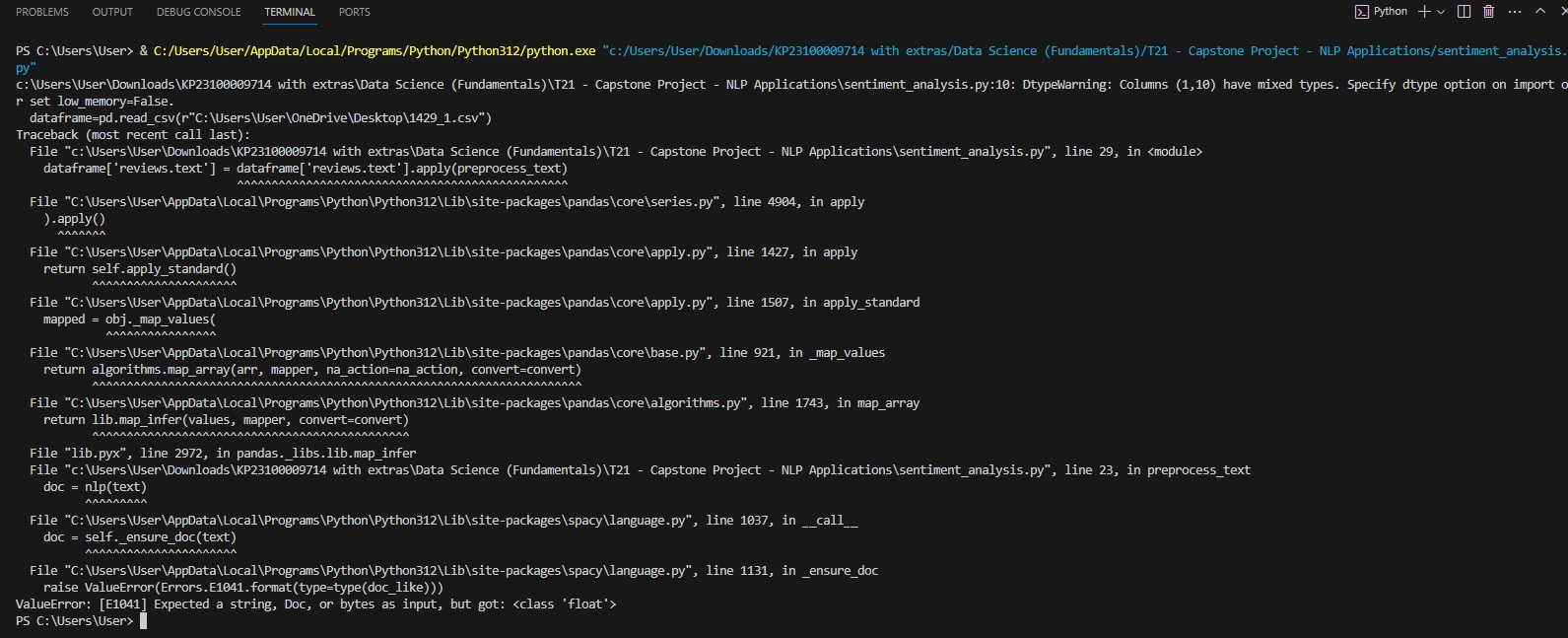
Error:PROBLEMS OUTPUT DEBUG CONSOLE TERMINAL PORTS
Python
py
set lowmemoryFalse.
dataframepdreadcsvrC: Users UserOneDrive Desktopcsv
Traceback most recent call last:
dataframereviewstext' dataframereviewstext'applypreprocesstext
apply
return self.applystandard
mapped obj.mapvalues
annanananananan
return algorithms.maparrayarr mapper, naactionnaaction, convertconvert
return lib.mapinfervalues mapper, convertconvert
File "lib.pyx line in pandas.libs.lib.mapinfer
doc nlptext
doc self.ensuredoctext
raise ValueErrorErrorsEformattypetypedoclike
ValueError: E Expected a string, Doc, or bytes as input, but got: class 'float'
PS C: VUsers User What do these mean and how do I correct these?
Step by Step Solution
There are 3 Steps involved in it
1 Expert Approved Answer
Step: 1 Unlock

Question Has Been Solved by an Expert!
Get step-by-step solutions from verified subject matter experts
Step: 2 Unlock
Step: 3 Unlock