

Question: design a HashTable.h, with insert{} deleteKey{} and query{} function, and complete MEMORYMANAGER_H and the main function To support memory-block releases and the coalescing of adjacent
design a HashTable.h, with insert{} deleteKey{} and query{} function, and complete MEMORYMANAGER_H and the main function
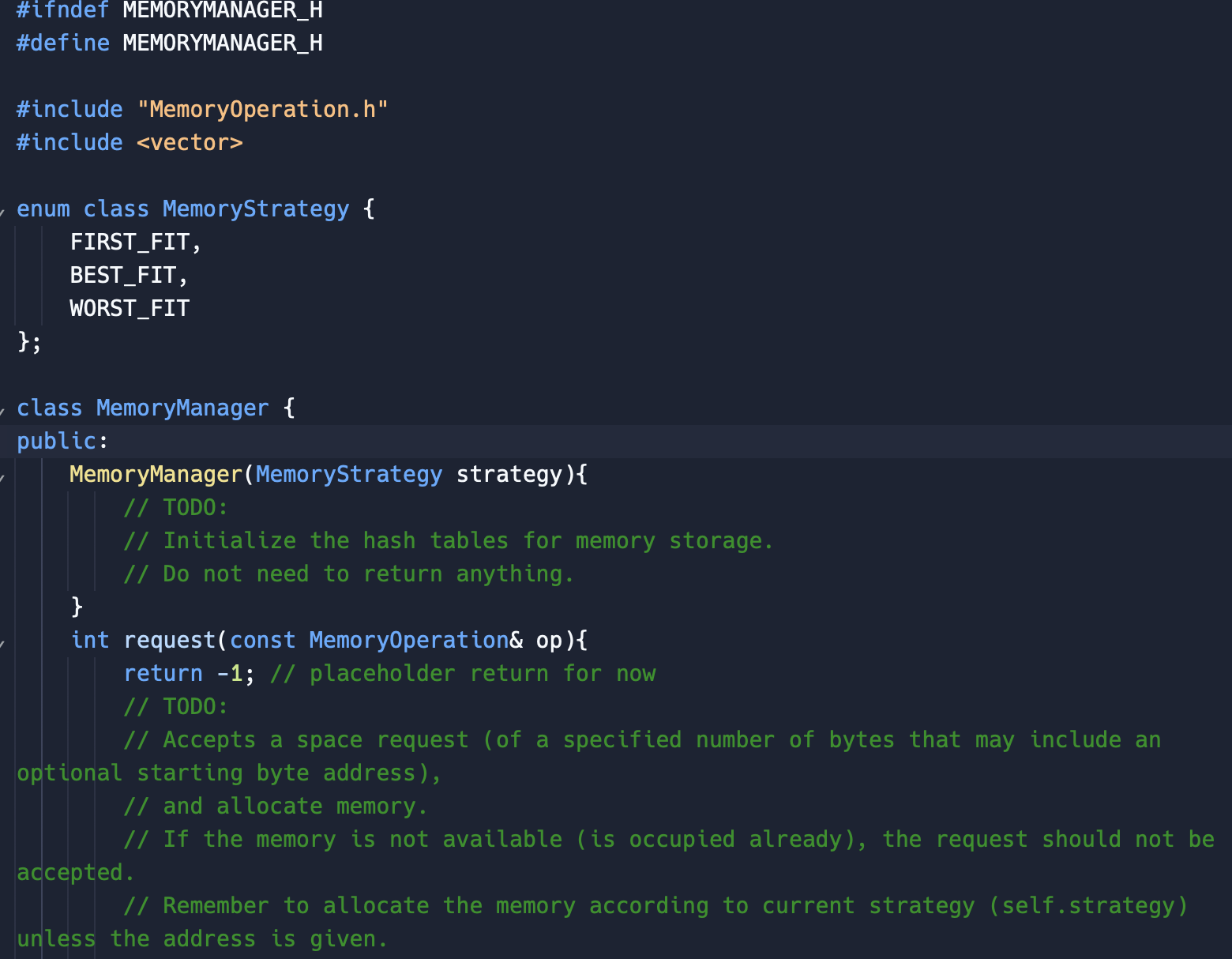
To support memory-block releases and the coalescing of adjacent free blocks into large blocks, you can design two hash tables to support these functions: one indexed on the starting address of a free block and another indexed on the size of each block.
To support memory-block requests, you can design a third hash table indexed on the starting address of the memory block allocated. Based on the information found, you can check whether the request is valid (say, not overlapping with any existing allocated blocks). This part is essential when the starting address of the request is specified.
All the three hash tables point to a common database (which is actually the physical memory allocated/free blocks). That is, the hash tables are just index tables by themselves. They are related because they all point to a shared database that stores blocks of memory allocated. Each block in the database contains information such as the physical memory address, protection status, processes owning the block, etc., otherwise not stored in the hash table. You may want to implement the shared database to avoid keeping this redundant information in each hash table.
For each hash table, you should create an initially empty hash table of m entries; each entry of the hash table should include fields for the forward and backward pointers of the linked list maintained by this table entry, the range of key values hashed into this location (b1,b2), the number of elements in the linked list pointed to by this table entry, and other fields if necessary. Note that a backward pointer is optional. It is included here for consistency with the lecture notes. An example of a hash table entry is as follows:
lower bound of upper bound of forward backward # entries in key range b1 key range b2 ptr to LL ptr to LL linked list
Each node in the linked list of the hash table entry should also include pertinent information on the memory block (such as whether it is free, its starting address, and its size. It would also have forward and backward pointers to other nodes in the linked list, if any. An example of a node in the linked list is as follows:
Backward pointer in LL forward pointer in LL memory block info.
You should populate each hash table with an initial set of memory-block allocations and releases.
You will then process the queries one at a time. As memory-block requests and releases with new keys may be inserted or existing records deleted, you must dynamically update the hash table as queries are processed.
You will report the result of each query, the times taken, and the number of logical steps (you need to decide how to measure the number of logical steps).
Since you need to search for keys in a specific range, you should divide the keys into ranges and use hashing on a range of keys into a unique hash table location. Each hash table entry should contain a range of keys that can be hashed into and a pointer to a linked list of the records in this list.
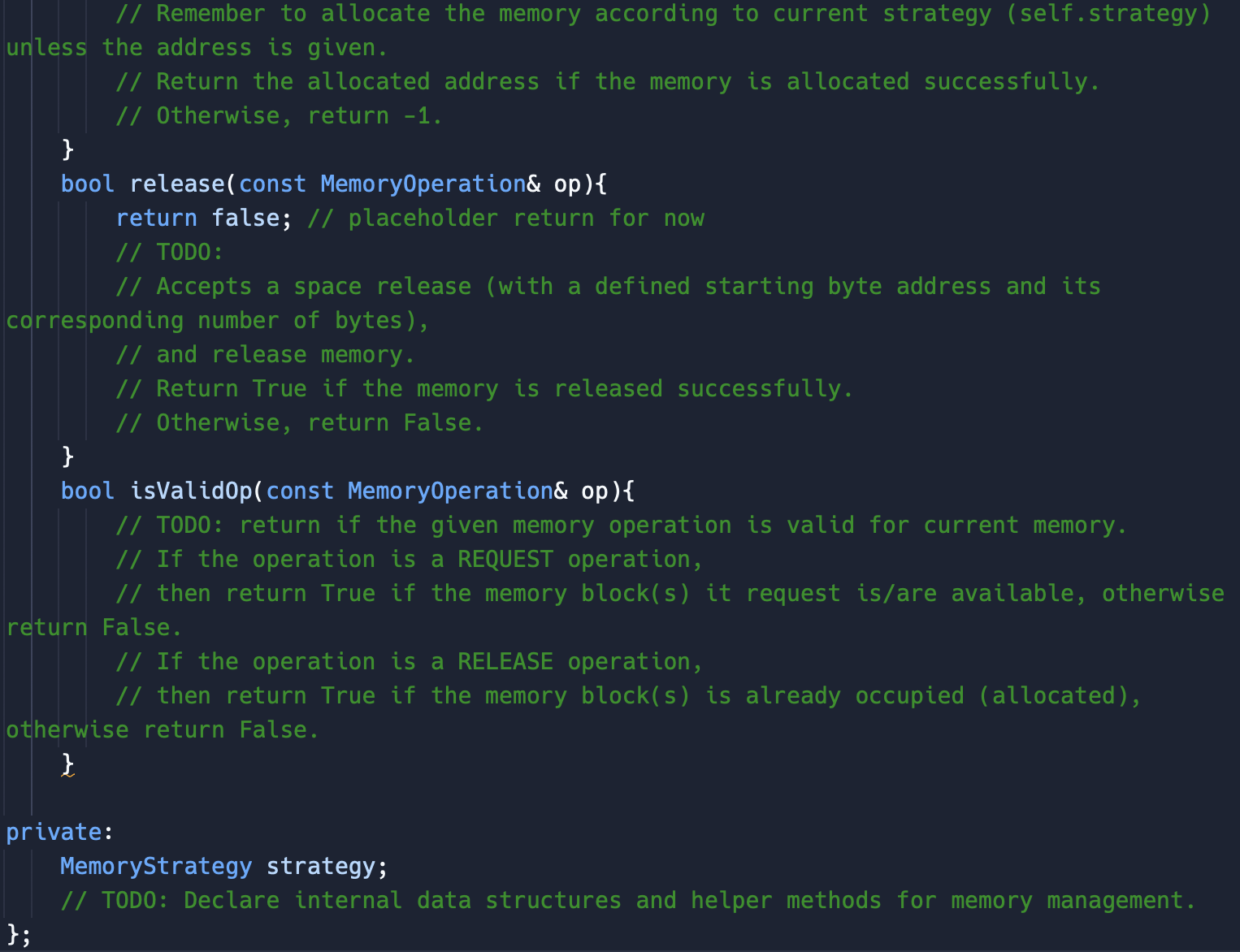
By adequately modifying the hash tables, You must decide how to support the best-fit, the first-bit, and the worst-fit strategy.
(a) First-fit: find the first available free block of space that fits the re- quest, with possibly some left-over unused space.
(b) Best-fit: find the best available free block of space that leaves the least unused space. This strategy requires finding the block of free space with the minimum wasted free space after allocation. (The goal is to minimize the wasted free space. The downside is that it leads to many small blocks of free space in the memory.)
(c) Worst-fit: find the best available free block of space that leaves the most unused space. This strategy requires finding the block of free space with the maximum unused space after allocation. (The goal is to keep the unallocated blocks of free space as large as possible.)
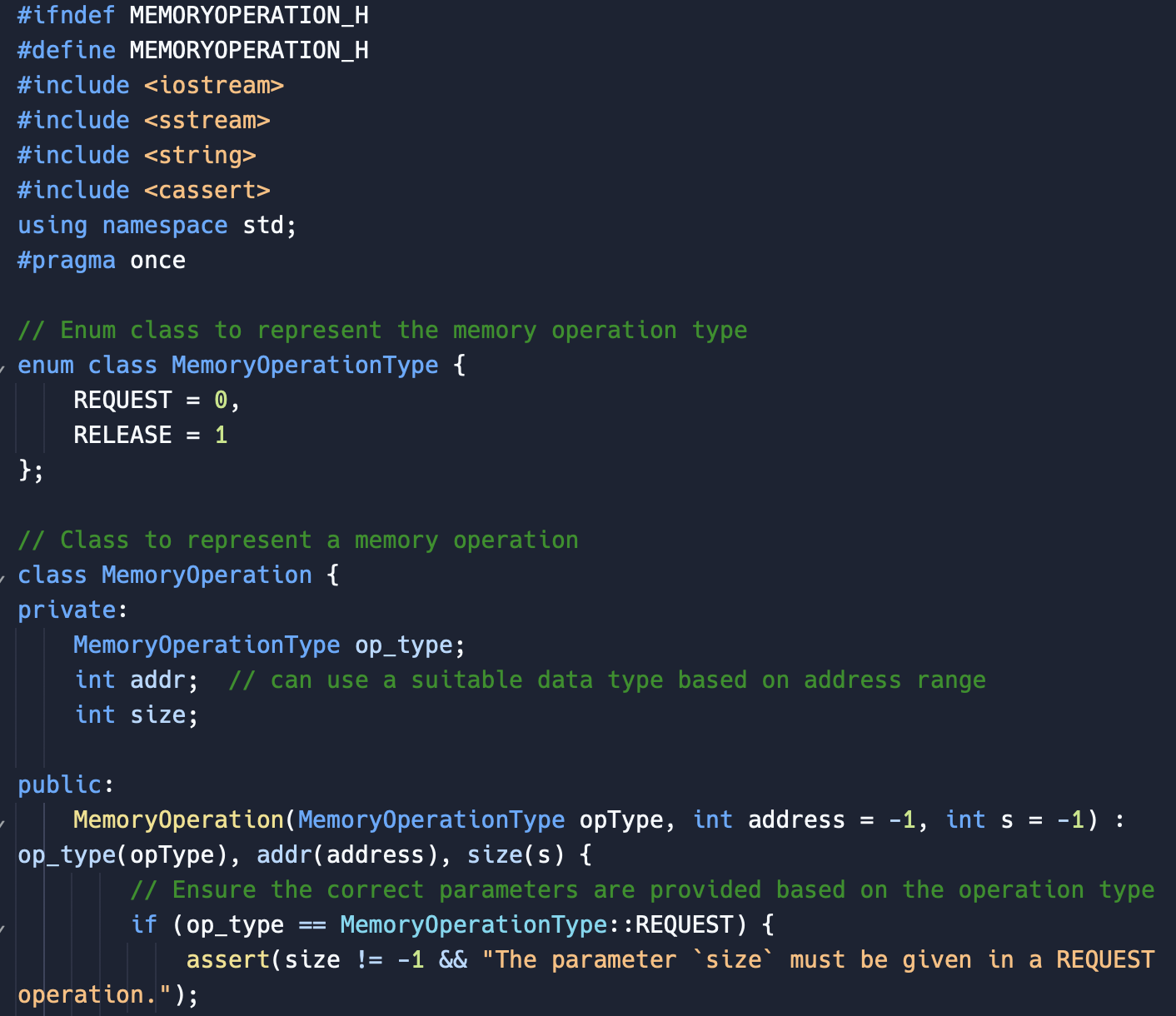
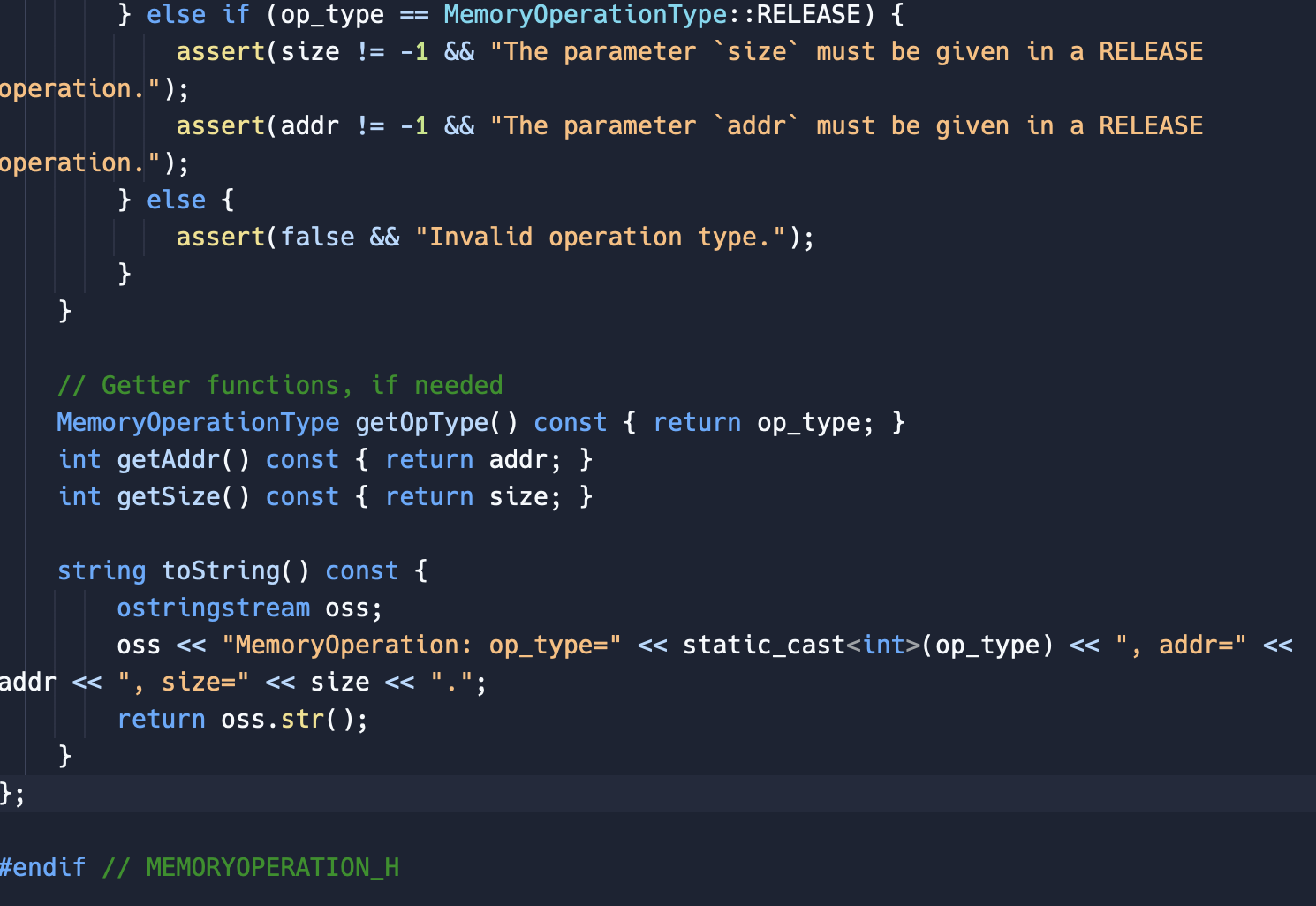
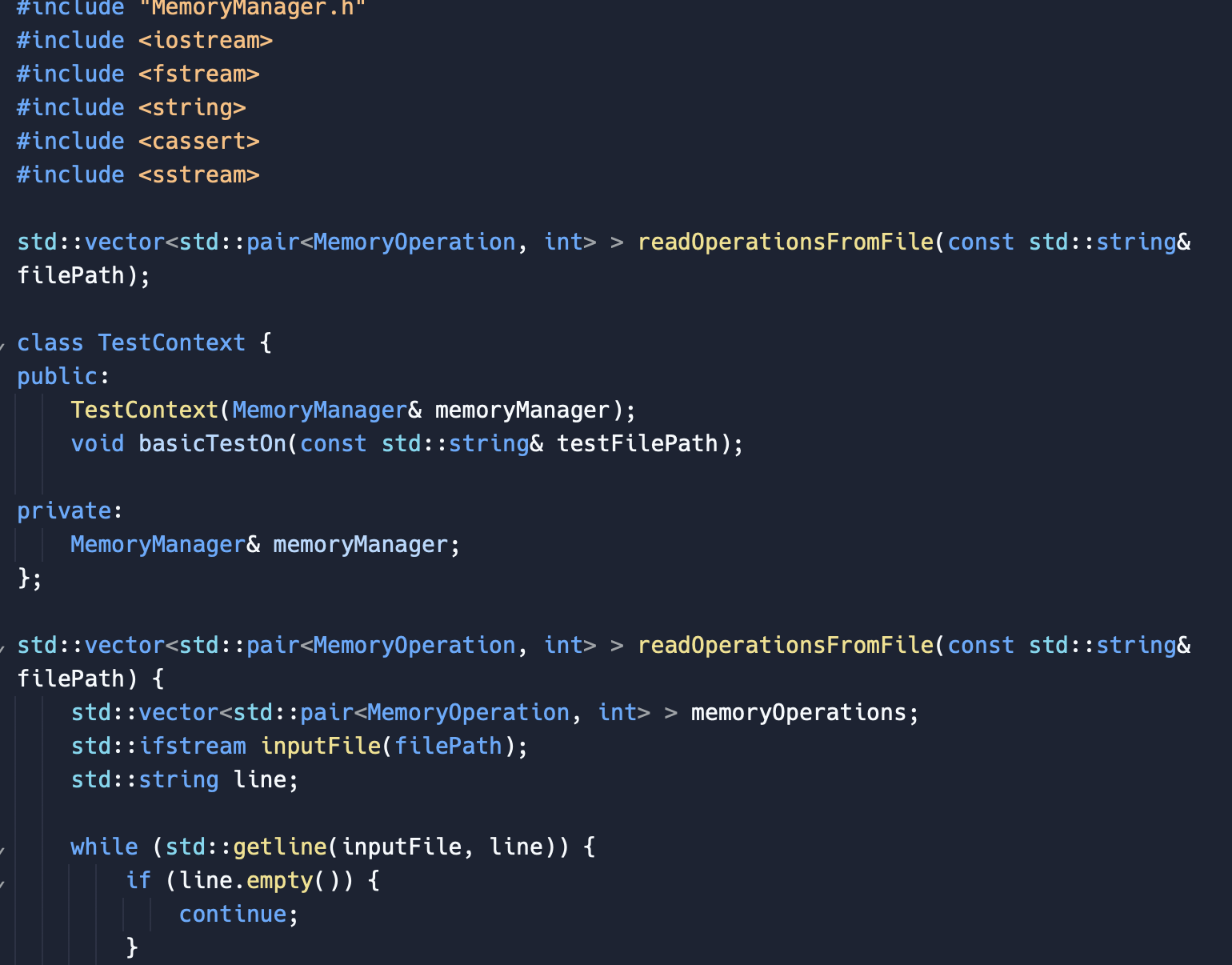
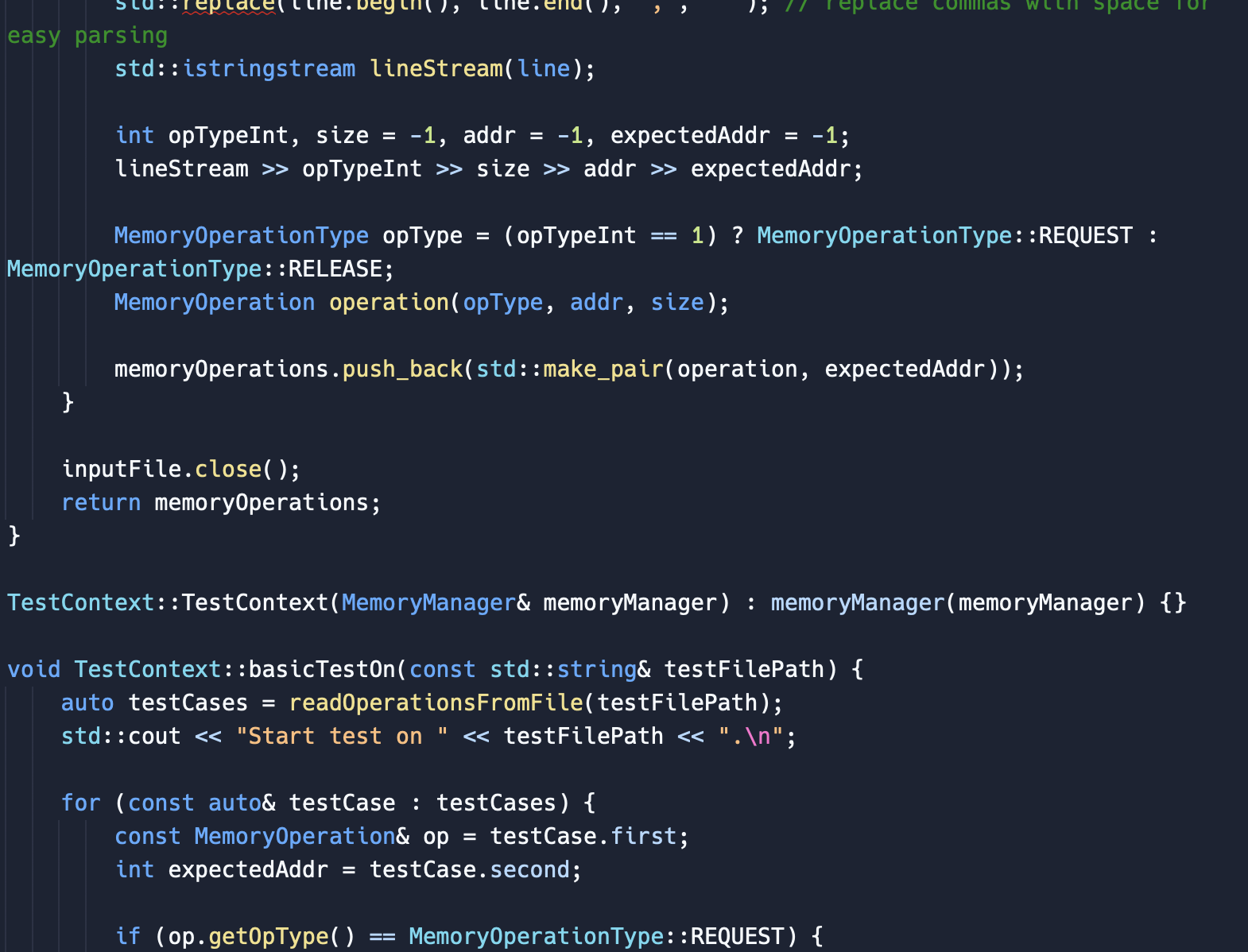
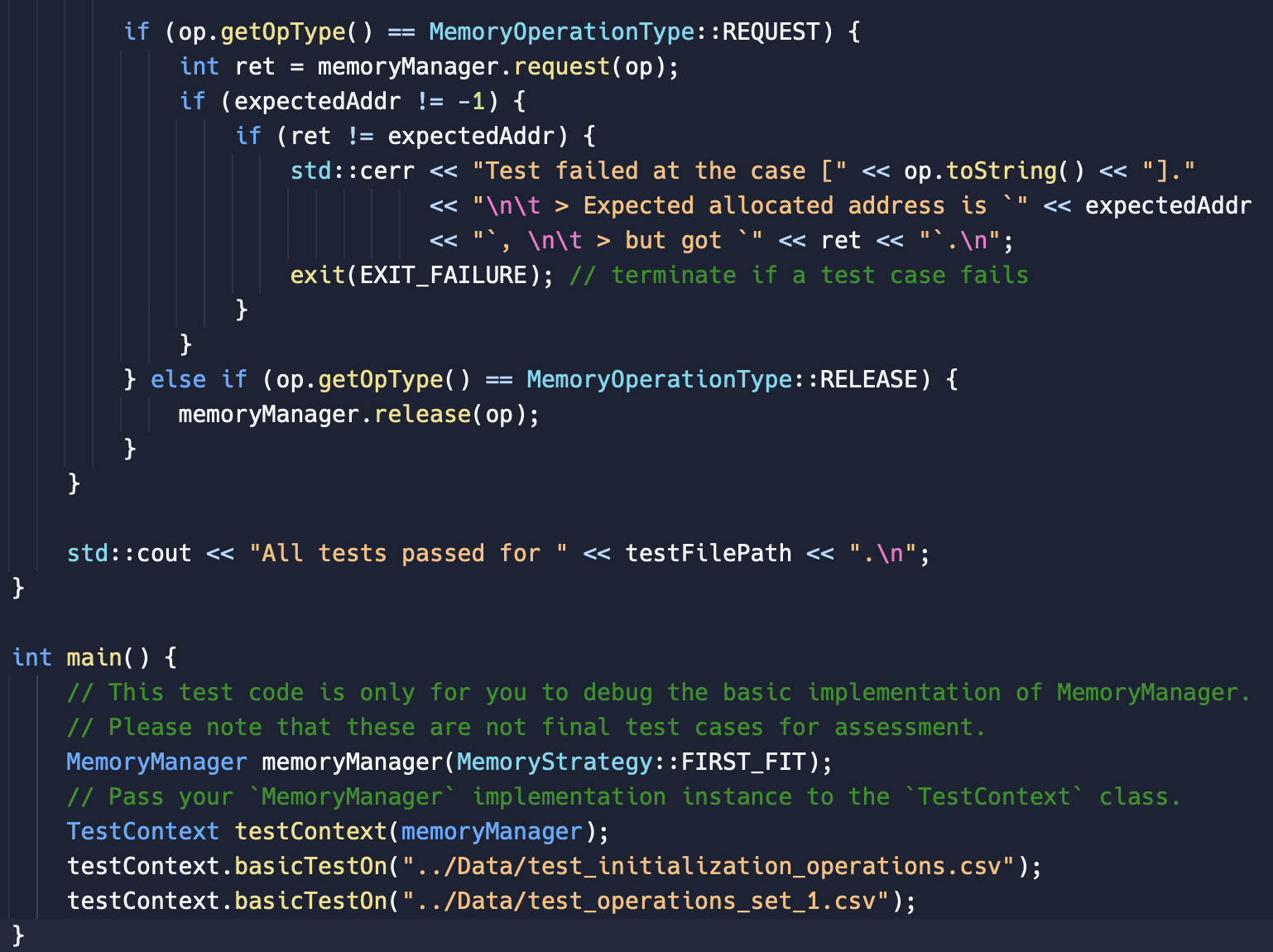
\#ifndef MEMORYOPERATION_H \#define MEMORYOPERATION_H \#include \#include \#include \#include using namespace std; \#pragma once // Enum class to represent the memory operation type enum class MemoryOperationType \{ REQUEST =0, RELEASE =1 \}; // Class to represent a memory operation class Memoryoperation \{ private: MemoryOperationType op_type; int addr; // can use a suitable data type based on address range int size; public: MemoryOperation(MemoryOperationType opType, int address =1, int s=1 ) : op_type(opType), addr(address), size(s) \{ // Ensure the correct parameters are provided based on the operation type if (op_type == MemoryOperationType::REQUEST) \{ assert(size != -1 \&\& "The parameter 'size' must be given in a REQUEST operation."); \} else if (op_type == MemoryOperationType::RELEASE) \{ assert(size != -1 \&\& "The parameter 'size' must be given in a RELEASE peration."); assert(addr != -1 \&\& "The parameter 'addr' must be given in a RELEASE peration."); \} else \{ assert(false \&\& "Invalid operation type."); \} \} // Getter functions, if needed MemoryOperationType getOpType() const \{ return op_type; \} int getAddr() const \{ return addr; \} int getSize( ) const \{ return size; \} string toString() const \{ ostringstream oss; oss (op_type) readOperationsFromFile(const std::string\& filePath); class TestContext \{ public: TestContext(MemoryManager\& memoryManager); void basicTeston(const std::string\& testFilePath); private: MemoryManager\& memoryManager; \}; std::vector > read0perationsFromFile(const std::string\& filePath) \{ std::vector > memory0perations; std::ifstream inputFile(filePath); std::string line; while (std::getline(inputFile, line)) \{ if (line.empty()) \{ continue; easy parsing std: : istringstream lineStream(line); int opTypeInt, size =1, addr =1, expectedAddr =1; MemoryOperationType opType = (opTypeInt == 1) ? MemoryOperationType::REQUEST : MemoryOperationType: :RELEASE; Memory0peration operation(opType, addr, size); memory0perations.push_back(std::make_pair(operation, expectedAddr)); \} inputFile.close( ); return memory0perations; \} TestContext: :TestContext(MemoryManager\& memoryManager) : memoryManager(memoryManager) \{\} void TestContext::basicTestOn(const std::string\& testFilePath) \{ auto testCases = readOperationsFromFile(testFilePath); std: :cout
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts