

Question: Evaluating Hypotheses and Decision Tree a) We trained two classifiers, Decision Tree with 350 examples and tested with 30 examples; and the Support Vector Machine
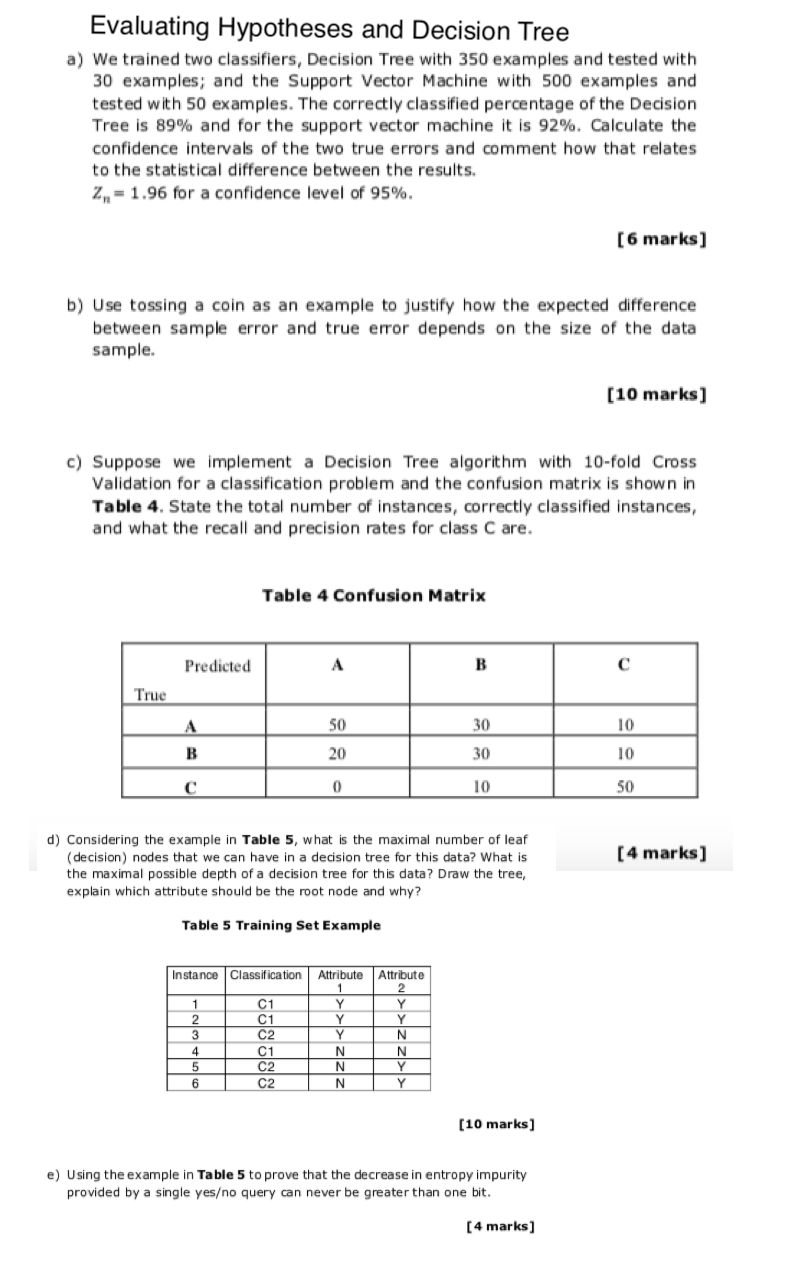
Evaluating Hypotheses and Decision Tree a) We trained two classifiers, Decision Tree with 350 examples and tested with 30 examples; and the Support Vector Machine with 500 examples and tested with 50 examples. The correctly classified percentage of the Decision Tree is 89% and for the support vector machine it is 92%. Calculate the confidence intervals of the two true errors and comment how that relates to the statistical difference between the results. 2= 1.96 for a confidence level of 95%. [6 marks) b) Use tossing a coin as an example to justify how the expected difference between sample error and true error depends on the size of the data sample. [10 marks] Suppose implement a Decision Tree algorithm with 10-fold Cross Validation for a classification problem and the confusion matrix is shown in Table 4. State the total number of instances, correctly classified instances, and what the recall and precision rates for class C are. Table 4 Confusion Matrix Predicted A B True A 50 30 10 20 30 10 C 0 10 50 [4 marks] d) Considering the example in Table 5, what is the maximal number of leaf (decision) nodes that we can have in a decision tree for this data? What is the maximal ssible of a decision tree for this data? Draw the tree explain which attribute should be the root node and why? Table 5 Training Set Example Instance Classification Attribute Attribute 1 2 3 4 5 6 C1 C1 C2 C1 C2 C2 Y Y Y N N N Y Y N N Y Y [10 marks] e) Using the example in Table 5 to prove that the decrease in entropy impurity provided by a single yeso query can never be greater than one bit. [4 marks]
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts