

Question: Ex 5 . 4 : Activation and weight scaling. Consider the two hidden unit network shown in Figure 5 . 6 2 , which uses
Ex : Activation and weight scaling. Consider the two hidden unit network shown in
Figure which uses ReLU activation functions and has no additive bias parameters. Your
task is to find a set of weights that will fit the function
Can you guess a set of weights that will fit this function?
Starting with the weights shown in column compute the activations for the hid
den and final units as well as the regression loss for the nine input values
Now compute the gradients of the squared loss with respect to all six weights using the
backpropagation chain rule equations and sum them up across the training
samples to get a final gradient.
What step size should you take in the gradient direction, and what would your update
squared loss become?
Repeat this exercise for the initial weights in column c of Figure
Given this new set of weights, how much worse is your error decrease, and how many
iterations would you expect it to take to achieve a reasonable solution?
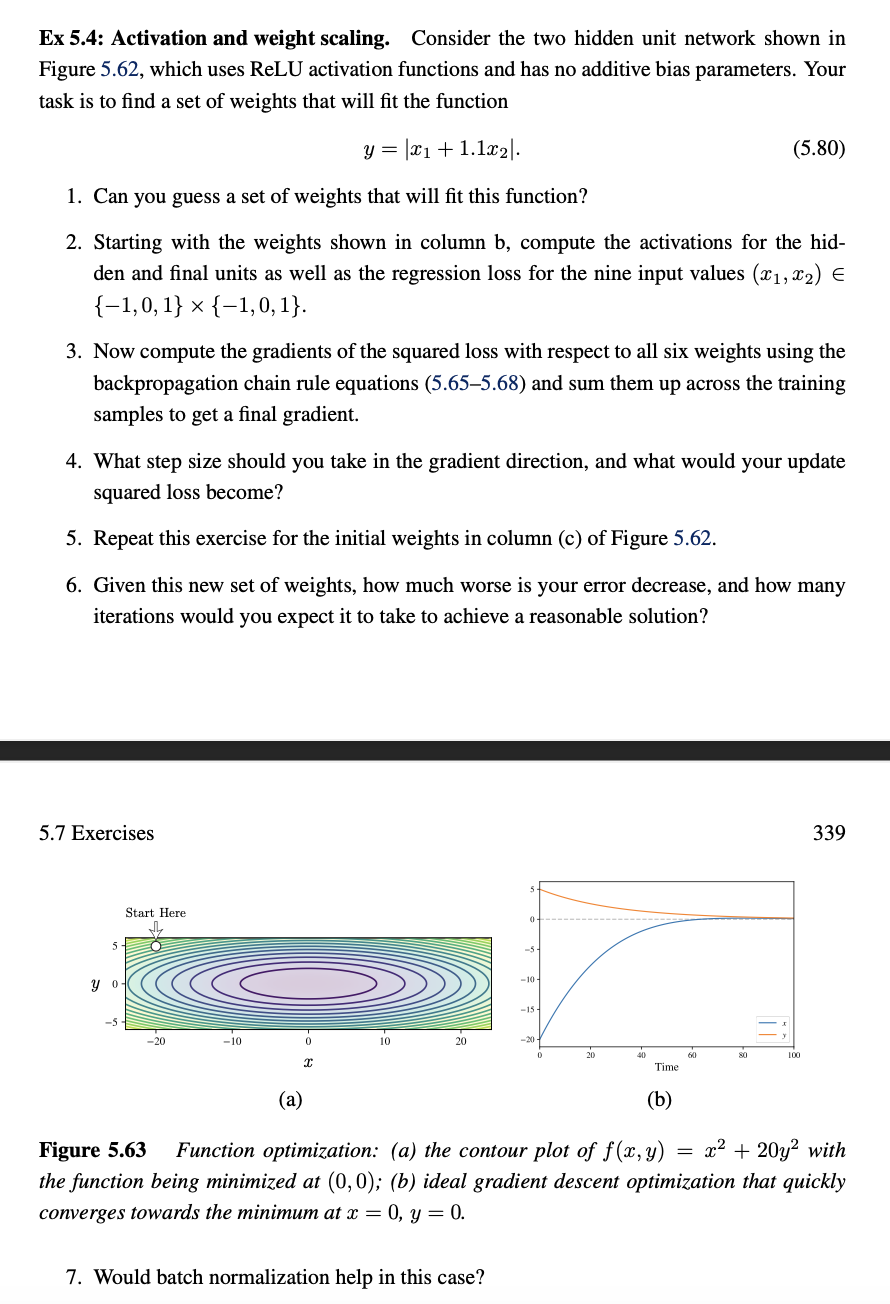
Figure Function optimization: a the contour plot of with
the function being minimized at ; b ideal gradient descent optimization that quickly
converges towards the minimum at
Would batch normalization help in this case?
Step by Step Solution
There are 3 Steps involved in it
1 Expert Approved Answer
Step: 1 Unlock

Question Has Been Solved by an Expert!
Get step-by-step solutions from verified subject matter experts
Step: 2 Unlock
Step: 3 Unlock