

Question: Finally, we combine all the previous steps into one model. We repeatedly find the closest centroid for each data points, and then update the centroids,
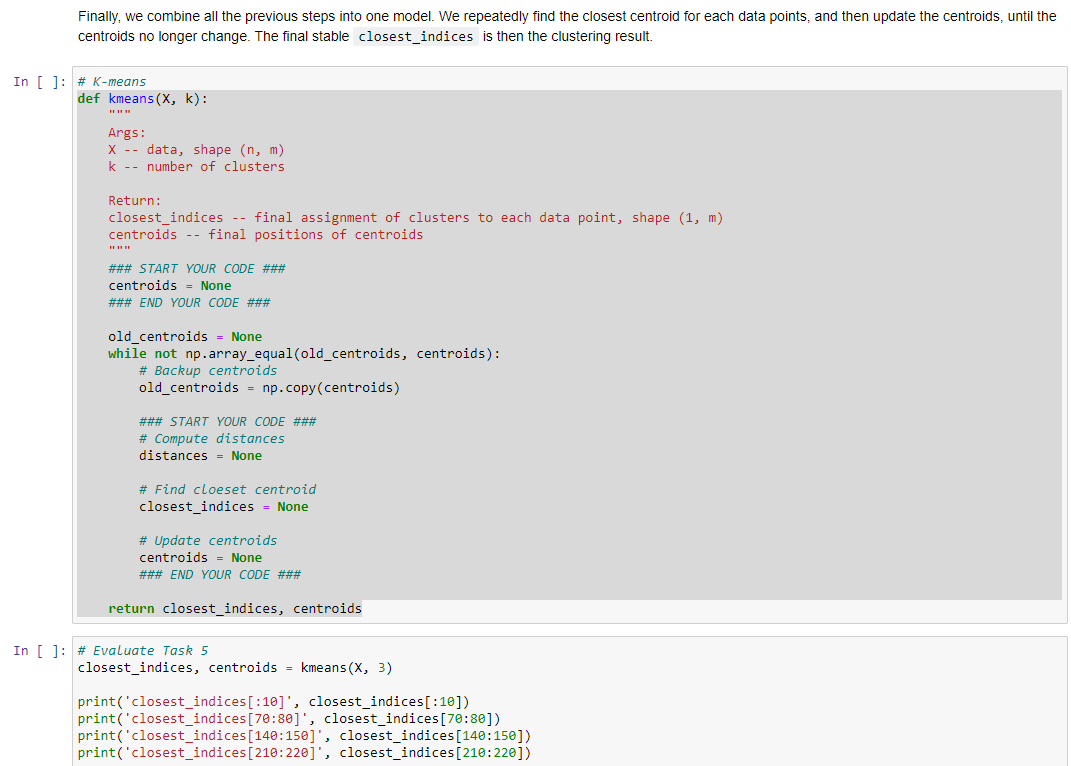
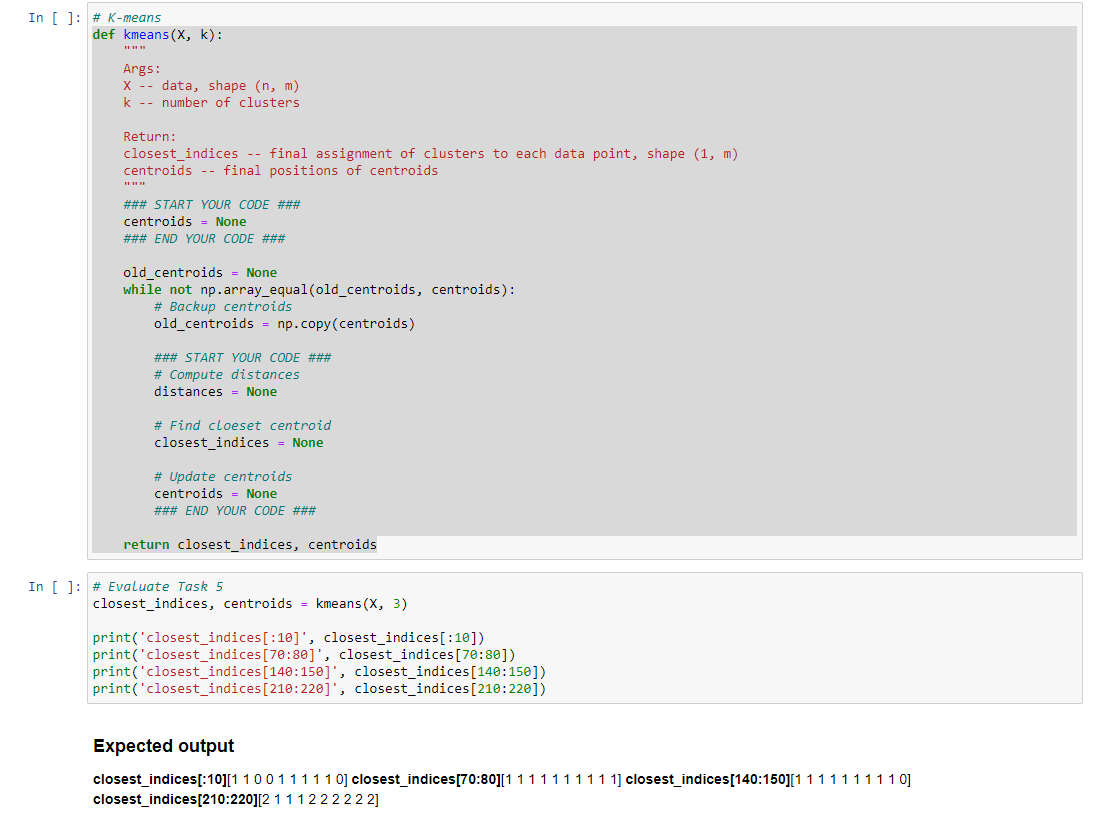
Finally, we combine all the previous steps into one model. We repeatedly find the closest centroid for each data points, and then update the centroids, until the centroids no longer change. The final stable closest_indices is then the clustering result. K-means ef kmeans (X,k) : Args: x - data, shape (n,m) k - number of clusters Return: closest_indices -. final assignment of clusters to each data point, shape (1, m) centroids -. final positions of centroids "wn \#\# START YOUR CODE \#\#\# centroids = None \#\#\# END YOUR CODE \#\#\# old_centroids = None while not np.array_equal(old_centroids, centroids): \# Backup centroids old_centroids =np copy (centroids) \#\#\# START YOUR CODE \#\#\# * Compute distances distances = None \# Find cloeset centroid closest_indices = None * Update centroids centroids = None \#\#\# END YOUR CODE \#\#\# return closest_indices, centroids
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts