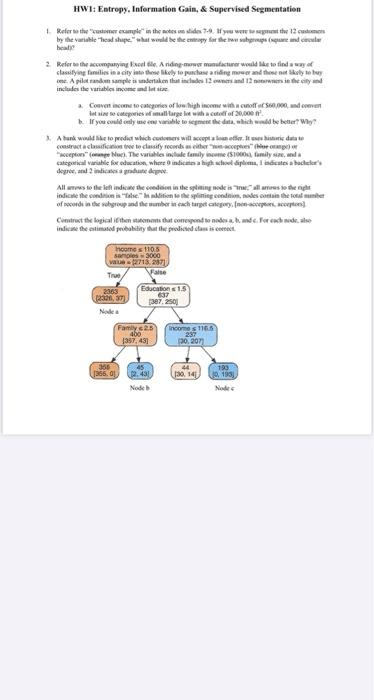
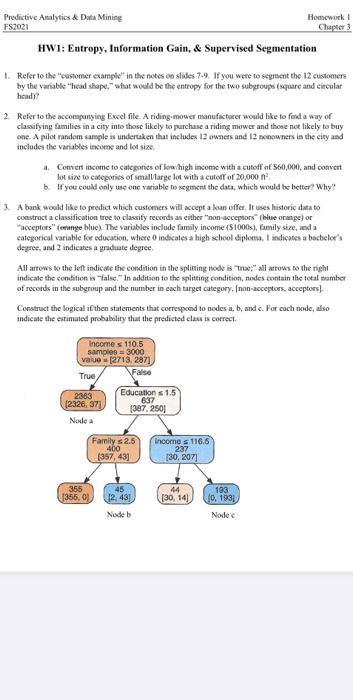
HWI: Entropy. Information Gain, & Supervised Segmentation Refer to the couple in the side www the 12 cm by the variable to superheld be they for the upper and cele heatre 2 Refer to the accompanying rolle Anding manufacturer would like to tind a way classifying is in a city into these key to purchase anding mower and those net kely to buy me. A pilot random sample is undertaken to des 13.12 includes the variable income and bette Coeven income to cater of high income with a cunoff.com Batteries are with 30,000 If you could only enable to see the data which will be better? Why A hunk would be to predict which comes will acceptate. It shtetic de construct a classifica todasify riscope iepong Ned. The viables de family come (1000, family sized categorical variable for education , where indicate aligh diploma, indicates a bedele degree indicare All the left indicate the code in the spinge alles so the indicate the conceition to the spingendades con the totale of code in the ground the womber in each target cregon Contract the topical then sements that correspond to nodeva. I made for each wedelse indie hemel bability that the product is een comes 110.5 samos3000 VaR 715.271 True False 2363 Education 1.5 230, 637 387.2501 Family 2.5 460 357.431 incomes 1165 287 130.207 358 366.00 130 248 0.14 136 Predictive Analytics & Data Mining FS2021 Homework! Chapter 3 HWI: Entropy, Information Gain, & Supervised Segmentation 1. Refer to the customer example in the notes on slides 7-9. If you were to segment the 12 customers by the variable "head shape, what would be the entropy for the two subgroups (spure and circular head? 2. Refer to the accompanying Excel file. A riding mower manufacturer would like to find a way of classifying families in a city into those likely to purchase a riding mower and those not likely to buy one. A pilot random sample is undertaken that includes 12 owners and 12 nenowners in the city and includes the variables income and lot size 3. Convert income to categories of low high income with a cutoff of 560,000, and convert lotsire to categories of small large lot with a cutoff or 20,000 If you could only use one variable to segment the data, which would be better? Why? 1 A bank would like to predict which customers will accept a loan offer It uses historic data to construct a classification tree to classity records as either non-acceptors" blue orange) or acceptors" unge blue) The variables include family income (S1000s), family size, anda categorical variable for education, where indicates a high school diploma, indicates a bachelor's degree, and indicates a graduate degree All arrows to the left indicate the condition in the splitting mode is true;" all arrows to the right indicate the condition is false. In addition to the splitting condition, nodes contain the total number of records in the subgroup and the number in each target category. (non-acceptors, acceptors). Construct the logical ifthen statements that correspond to nodes a, b, and c. For cach node, also indicate the estimated probability that the predicted class is correct Income s 110.5 samples 3000 value = [27132871 True 2383 Education s 1.5 12326, 37 637 (307. 250) Node a Family s 2.5 400 (357, 43) Income s 116.6 237 130, 207] 355 1355, 01 45 12.48 Nodeb 44 (30, 14) 193 10, 193 Node HWI: Entropy. Information Gain, & Supervised Segmentation Refer to the couple in the side www the 12 cm by the variable to superheld be they for the upper and cele heatre 2 Refer to the accompanying rolle Anding manufacturer would like to tind a way classifying is in a city into these key to purchase anding mower and those net kely to buy me. A pilot random sample is undertaken to des 13.12 includes the variable income and bette Coeven income to cater of high income with a cunoff.com Batteries are with 30,000 If you could only enable to see the data which will be better? Why A hunk would be to predict which comes will acceptate. It shtetic de construct a classifica todasify riscope iepong Ned. The viables de family come (1000, family sized categorical variable for education , where indicate aligh diploma, indicates a bedele degree indicare All the left indicate the code in the spinge alles so the indicate the conceition to the spingendades con the totale of code in the ground the womber in each target cregon Contract the topical then sements that correspond to nodeva. I made for each wedelse indie hemel bability that the product is een comes 110.5 samos3000 VaR 715.271 True False 2363 Education 1.5 230, 637 387.2501 Family 2.5 460 357.431 incomes 1165 287 130.207 358 366.00 130 248 0.14 136 Predictive Analytics & Data Mining FS2021 Homework! Chapter 3 HWI: Entropy, Information Gain, & Supervised Segmentation 1. Refer to the customer example in the notes on slides 7-9. If you were to segment the 12 customers by the variable "head shape, what would be the entropy for the two subgroups (spure and circular head? 2. Refer to the accompanying Excel file. A riding mower manufacturer would like to find a way of classifying families in a city into those likely to purchase a riding mower and those not likely to buy one. A pilot random sample is undertaken that includes 12 owners and 12 nenowners in the city and includes the variables income and lot size 3. Convert income to categories of low high income with a cutoff of 560,000, and convert lotsire to categories of small large lot with a cutoff or 20,000 If you could only use one variable to segment the data, which would be better? Why? 1 A bank would like to predict which customers will accept a loan offer It uses historic data to construct a classification tree to classity records as either non-acceptors" blue orange) or acceptors" unge blue) The variables include family income (S1000s), family size, anda categorical variable for education, where indicates a high school diploma, indicates a bachelor's degree, and indicates a graduate degree All arrows to the left indicate the condition in the splitting mode is true;" all arrows to the right indicate the condition is false. In addition to the splitting condition, nodes contain the total number of records in the subgroup and the number in each target category. (non-acceptors, acceptors). Construct the logical ifthen statements that correspond to nodes a, b, and c. For cach node, also indicate the estimated probability that the predicted class is correct Income s 110.5 samples 3000 value = [27132871 True 2383 Education s 1.5 12326, 37 637 (307. 250) Node a Family s 2.5 400 (357, 43) Income s 116.6 237 130, 207] 355 1355, 01 45 12.48 Nodeb 44 (30, 14) 193 10, 193 Node