

Question: I need a solution quickly please This question uses the same MDP as the previous question, repeated here for your convenience. Again, assume =0.5 Suppose
I need a solution quickly please 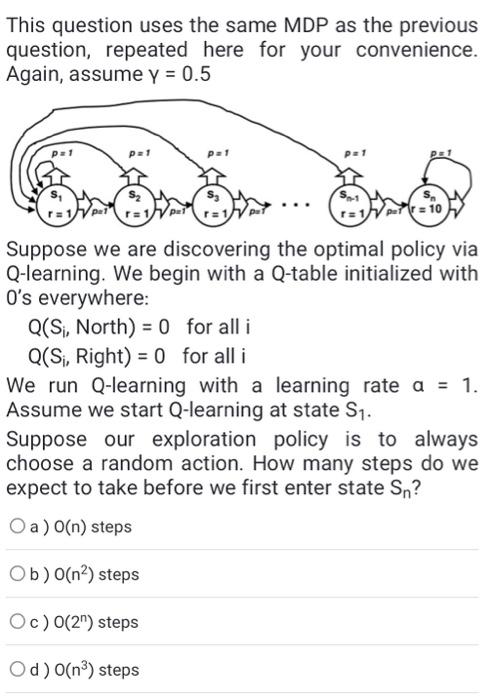
This question uses the same MDP as the previous question, repeated here for your convenience. Again, assume =0.5 Suppose we are discovering the optimal policy via Q-learning. We begin with a Q-table initialized with 0 's everywhere: Q(Si, North )=0 for all i Q(Si, Right )=0 for all i We run Q-learning with a learning rate a=1. Assume we start Q-learning at state S1. Suppose our exploration policy is to always choose a random action. How many steps do we expect to take before we first enter state Sn ? a) O(n) steps b ) O(n2) steps c ) O(2n) steps d ) O(n3) steps
Step by Step Solution
There are 3 Steps involved in it
1 Expert Approved Answer
Step: 1 Unlock

Question Has Been Solved by an Expert!
Get step-by-step solutions from verified subject matter experts
Step: 2 Unlock
Step: 3 Unlock