

Question: i need complete python code please have provided a function called normalize_token in import to normalize a single token from a string. For example, the
i need complete python code please

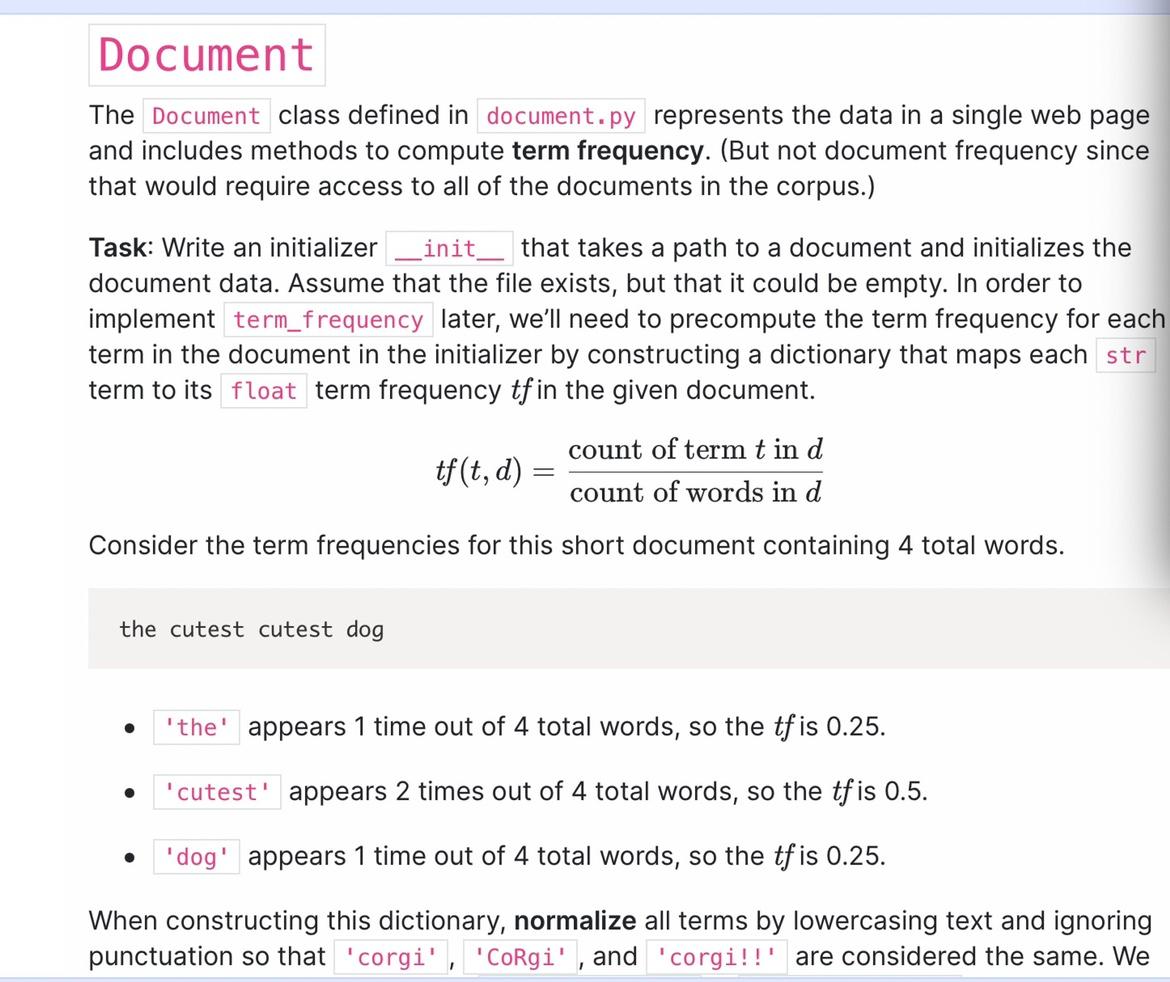
have provided a function called normalize_token in import to normalize a single token from a string. For example, the following code cells show how to use the function. token = 'CoRgi!!' token = normalize_token(token) print(token) \# corgi token = 'Hi!' token = normalize_token(token) print(token) \# divhidiv Info If you're familiar with HTML, you might have noticed that a lot of the files in our provided corpus contain HTML code, including tags that look like . Don't worry about handling the html. Sticking with what we provide above for normalization is enough. The class defined in represents the data in a single web page and includes methods to compute term frequency. (But not document frequency since that would require access to all of the documents in the corpus.) Task: Write an initializer that takes a path to a document and initializes the document data. Assume that the file exists, but that it could be empty. In order to implement later, we'll need to precompute the term frequency for each term in the document in the initializer by constructing a dictionary that maps each term to its term frequency tf in the given document. tf(t,d)=countofwordsindcountoftermtind Consider the term frequencies for this short document containing 4 total words. the cutest cutest dog - appears 1 time out of 4 total words, so the tf is 0.25. - appears 2 times out of 4 total words, so the tf is 0.5. - appears 1 time out of 4 total words, so the tf is 0.25. When constructing this dictionary, normalize all terms by lowercasing text and ignoring punctuation so that , and are considered the same. We
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts