

Question: Identify the tables, in your final schema, that are expected to be extremely large and are expected to grow over time. For each of these
Identify the tables, in your final schema, that are expected to be extremely large and are expected to grow over time. For each of these tables: • Describe the expected record size (in bytes or kilobytes), the estimated initial table size, and estimated table size after 10 years of use. • Describe a suitable storage strategy for such tables. Your answer must include the modified SQL DDL statements to define your chosen strategy.
2) Identify 3 common queries that would need to be run frequently against the database (at least 2 must include a join, and one must include a transaction with multiple steps). For each of the queries: • Produce the SQL to correctly produce the expected result. • Identify what indexes would help. Identify the type of index and columns that are used to build these indexes (justify your design). • Show the SQL commands for building these indexes in Oracle. • Show the query execution plans both before the index is added and after adding the index. • Explain how the index was utilised (or not) and why. What join algorithms were used? What changes would you need to make for the index to be properly utilised, or for a different join algorithm to be used instead? (Provide concrete details of the changes).
3) Describe a suitable partition strategy for extremely large tables you identified in step 1. Include details of the partitioning type and which columns/key should be used. You must include the SQL DDL statements used to implement your partition strategy. You must justify your design decisions. Include details about which of the above queries it will improve the performance of and how it helps with concrete examples. (You must explain in clear terms - such as partition pruning, partition joins, and parallel SQL, applicable to each of these queries.)
5) Before a voter is allowed to vote, to ensure the integrity of the election system, the system should check if he/she had voted earlier on this election. trigger - previouslyVoted(), to check if the voter had voted before. This trigger reads the election code, electorate, voter identification as inputs and returns a Boolean value (true, if voted before and false, if not voted before).
6) stored procedure - primaryVoteCount(), to complete the step 1 of the counting process. This stored procedure requires election code and electorate name as inputs. It will read Computerised Ballot Papers and does required processing, and update Election Results table with primary votes (first preferences) received by each candidate in chosen electorate in the chosen election.
7) stored procedure - distributePreferences(), to complete the step 2 of the counting process. This stored procedure requires election code and electorate name as inputs. It will read Computerised Ballot Papers and does required processing, and update Election Results table with preference votes received by each candidate at each preference distribution in chosen electorate in the chosen election.
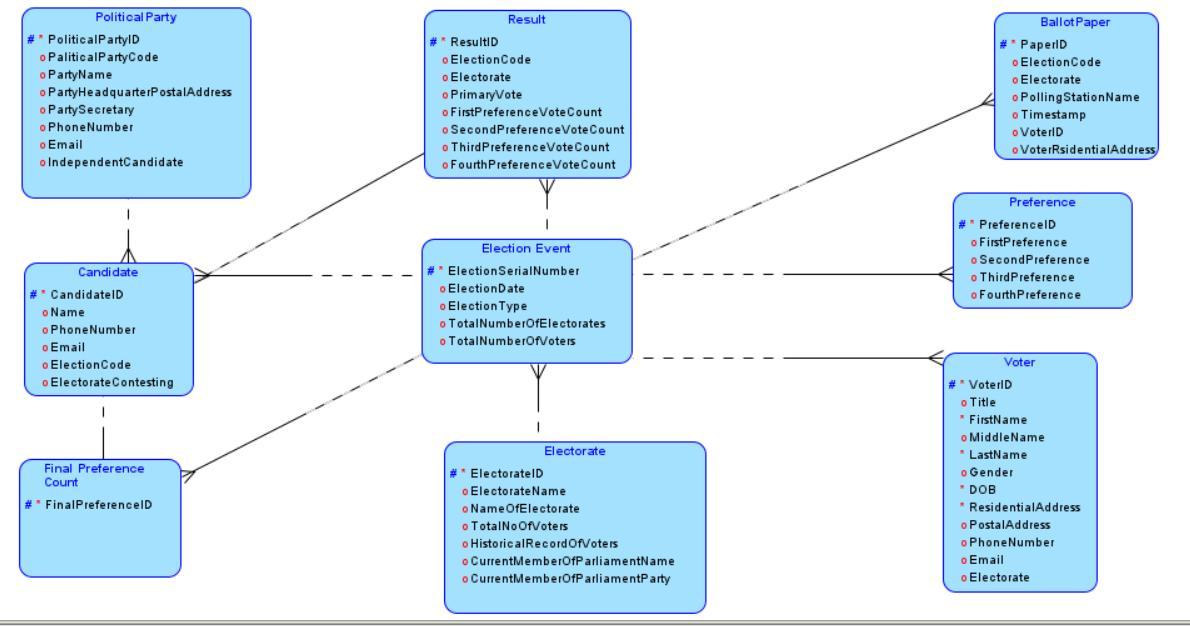
Political Party PoliticalPartyID o PaliticalPartyCode o PartyName o PartyHeadquarterPostalAddress o Party Secretary o Phone Number o Email o IndependentCandidate ResultID Result o ElectionCode o Electorate o PrimaryVote oFirstPreference Vote Count o Second Preference Vote Count o Third Preference Vote Count oFourth PreferenceVote Count Ballot Paper PaperID ElectionCode o Electorate o Polling StationName o Timestamp o VoterID VoterRsidentialAddress Candidate CandidateID Name o PhoneNumber o Email o Election Code o Electorate Contesting Final Preference Count #FinalPreferenceID Election Event ElectionSerialNumber o Election Date Election Type o TotalNumberOfElectorates o TotalNumberOfVoters Preference PreferenceID o FirstPreference SecondPreference o ThirdPreference o Fourth Preference ElectorateID Electorate o Electorate Name o Name OfElectorate o TotalNoOfVoters o Historical Record OfVoters o CurrentMemberOfParliamentName o CurrentMemberOfParliamentParty Voter * VoterID o Title * FirstName o MiddleName "LastName o Gender DOB *ResidentialAddress o PostalAddress o Phone Number o Email o Electorate
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts