

Question: import numpy as np #machine learning tool used for efficient array processing import pandas as pd #machine learning tool used for data sets and data
import numpy as np #machine learning tool used for efficient array processing
import pandas as pd #machine learning tool used for data sets and data frames
from sklearn.modelselection import traintestsplit #traditional machine learning
from sklearn.featureextraction.text import TfidfVectorizer#text is converted into vectrorizeor numbers to feed into computer
#tfhow much times a term is repeated,idfinverse documentry frequencyno of documentsno of documents has the term
from sklearn.linearmodel import PassiveAggressiveClassifier # this is for text classification
from sklearn.metrics import accuracyscore, confusionmatrix #for result
# Read the data
df pdreadcsvcontentfakeorrealnews.csv #reading the data and lebelling them,for accuracy
# Get shape and head
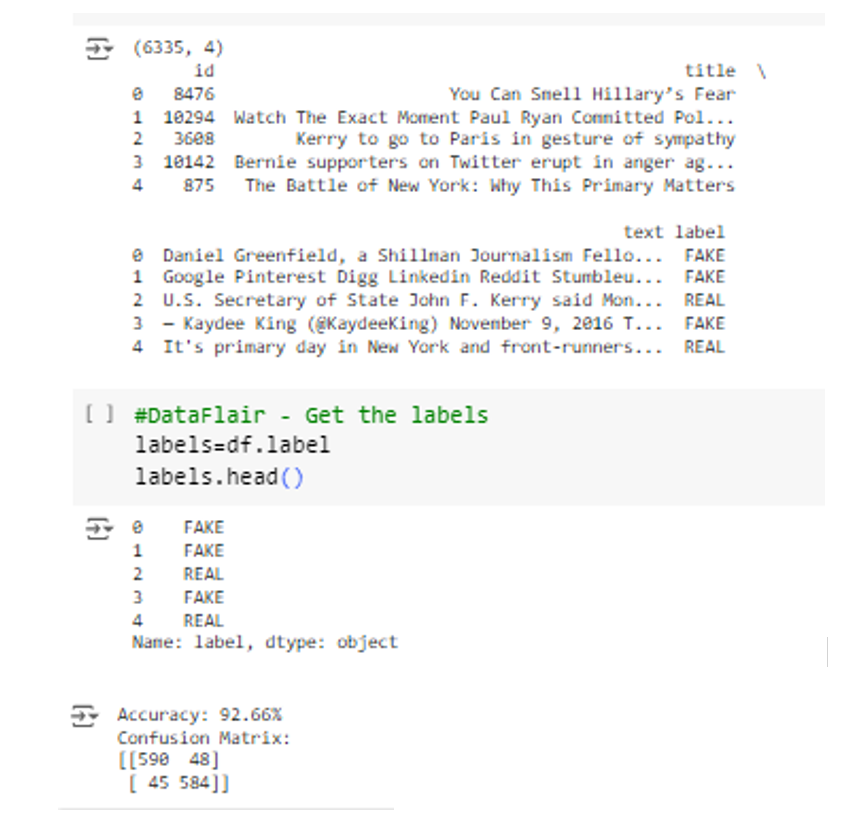
printdfshape#This line prints the shape of the DataFrame df which represents the number of rows and columns in the DataFrame.
printdfhead# This line prints the first few rows of the DataFrame df By default, it prints the first rows
#DataFlair Get the labels
labelsdflabel
labels.head
class TextClassification:
def initself df labels:#here we split the data into train and test so that we can see the accurcy
self.df df #df pandasDataFrame:The DataFrame containing the text data and labels.
self.labels labels #The Series containing the labels target variable
self.xtrain, self.xtest, self.ytrain, self.ytest traintestsplitdftext labels, testsize randomstate# Split data into training and testing sets train, test
self.tfidfvectorizer TfidfVectorizerstopwords'english', maxdf# Create a TFIDF vectorizer with English stop words removed and a maximum document frequency threshold of
self.tfidftrain None
self.tfidftest None
self.pac PassiveAggressiveClassifiermaxiter# Instantiate a PassiveAggressiveClassifier with a maximum number of iterations of
def preprocessdataself:#Preprocesses the text data using TFIDF vectorization.
self.tfidftrain self.tfidfvectorizer.fittransformselfxtrain
self.tfidftest self.tfidfvectorizer.transformselfxtest
def trainmodelself:#Trains the text classification model using the PassiveAggressiveClassifier.
self.pac.fitselftfidftrain, self.ytrain
def evaluatemodelself:#Evaluates the trained model's performance using accuracy and confusion matrix.
ypred self.pac.predictselftfidftest
score accuracyscoreselfytest, ypred
printfAccuracy: roundscore
confusionmat confusionmatrixselfytest, ypred, labelsFAKE 'REAL'
printConfusion Matrix:"
printconfusionmat
if namemain:
# Sample usage
df pdreadcsvcontentfakeorrealnews.csv
labels dflabel
# Create an instance of TextClassification
classifier TextClassificationdf labels
# Preprocess the data
classifier.preprocessdata
# Train the model
classifier.trainmodel
# Evaluate the model
classifier.evaluatemodelthis is code and output screenshot for fake news detection using python pls do provide with detailed ellaborate content for Abstract
Introduction
Methodology
Results Results Screenshot
Conclusion for this project
Step by Step Solution
There are 3 Steps involved in it
1 Expert Approved Answer
Step: 1 Unlock

Question Has Been Solved by an Expert!
Get step-by-step solutions from verified subject matter experts
Step: 2 Unlock
Step: 3 Unlock