

Question: import pandas as pd def load _ ticket _ data ( ) : file _ paths 'AnnArbor - TicketViolation 2 0 1 7 . xIs',
import pandas as pd
def loadticketdata:
filepaths
'AnnArborTicketViolationxIs',
'AnnArborTicketViolationjanxIs',
'AnnArborTicketViolationxIs',
'AnnArborTicketViolationxIs',
'AnnArborTicketViolationxIs',
'AnnArborTicketViolationxIs'
dflist
totalrows
for filepath in filepaths:
if in filepath:
df pdreadcsvfilepath, header skipfooter # Skip footer row for
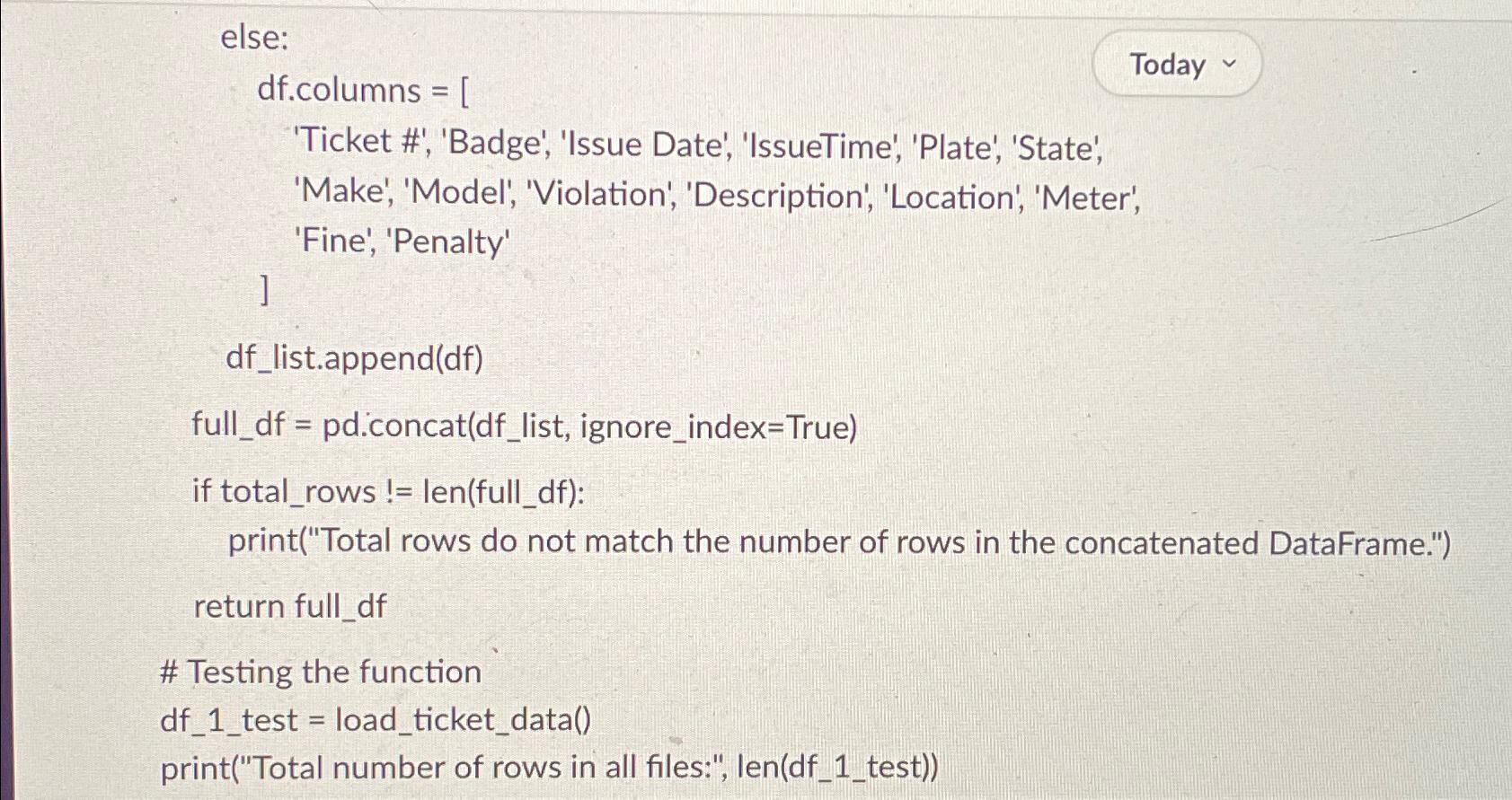
else:
xls ExcelFilefilepath
sheetsnamesxlssheetnames
dfpdDataFrame
for sheetname in sheetnames:
sheetdfpdreadexcelfilepath, sheetnamesheetname, headerNone, skipfooter
if sheetname in Sheet 'Sheet and sheetdfcolumns: sheetdf sheetdfiloc: # Skip the first row for sheet and sheet of pdconcatdf sheetdf ignoreindexTrue
totalrows lendf
if in filepath:
dfrenamecolumns Fine : "Fine" inplaceTrue
else:
dfcolumns
'Ticket # 'Badge', 'Issue Date', 'IssueTime', 'Plate', 'State',
'Make', 'Model', 'Violation', 'Description', 'Location', 'Meter',
'Fine', 'Penalty'
dflist.appenddf
fulldf pdconcatdflist, ignoreindexTrue
if totalrows lenfulldf:
printTotal rows do not match the number of rows in the concatenated DataFrame."
return fulldf
# Testing the function
dftest loadticketdata
printTotal number of rows in all files:", lendftest
Cannot get correct answer
Step by Step Solution
There are 3 Steps involved in it
1 Expert Approved Answer
Step: 1 Unlock

Question Has Been Solved by an Expert!
Get step-by-step solutions from verified subject matter experts
Step: 2 Unlock
Step: 3 Unlock