

Question: import pandas as pd import csv import nltk from collections import Counter 1. Find the most frequent bigrams 2. Find the most frequent skipgrams 3.
import pandas as pd import csv
import nltk
from collections import Counter
1. Find the most frequent bigrams
2. Find the most frequent skipgrams
3. Shingling
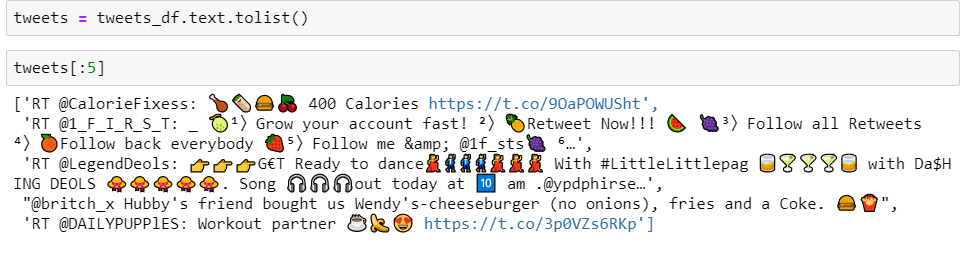
![work well? tweets = tweets_df.text. tolist() tweets[:5] ['RT @CalorieFixess: 400 Calories https://t.co/90aPOWUSht',](https://dsd5zvtm8ll6.cloudfront.net/si.experts.images/questions/2024/09/66f5256c32f71_93166f5256bbdc06.jpg)

What should I put in #Your Code Here? Do it work well?
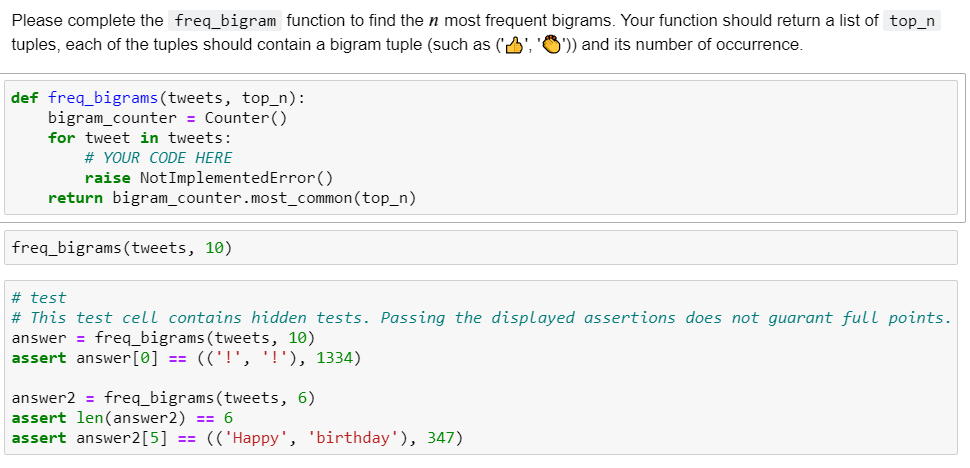
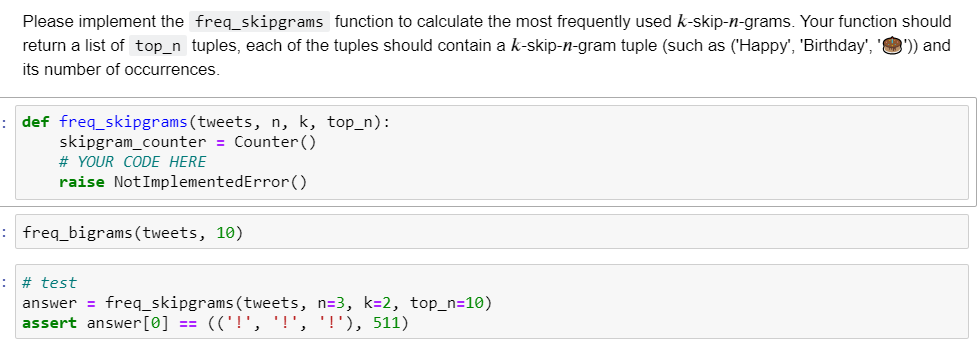
tweets = tweets_df.text. tolist() tweets[:5] ['RT @CalorieFixess: 400 Calories https://t.co/90aPOWUSht', 'RT @1_F_I_R_S_T: 1) Grow your account fast! 2) Retweet Now!!! 3) Follow all Retweets 4) Follow back everybody 5) Follow me & @1f_sts ...', 'RT @LegendDeols: To Get Ready to dance with #LittleLittlepag 08880 with Da$H ING DEOLS A Song out today at 10 am - @ypdphirse...', "@britch_x Hubby's friend bought us Wendy's-cheeseburger (no onions), fries and a Coke. RT @DAILYPUPPIES: Workout partner https://t.co/3POVZs6RKp'] Please complete the freq_bigram function to find the n most frequent bigrams. Your function should return a list of top_n tuples, each of the tuples should contain a bigram tuple (such as 'B',')) and its number of occurrence. def freq_bigrams (tweets, top_n): bigram_counter = Counter for tweet in tweets: # YOUR CODE HERE raise Not ImplementedError() return bigram_counter.most_common(top_n) freq_bigrams (tweets, 10) # test # This test cell contains hidden tests. Passing the displayed assertions does not guarant full points. answer = freq_bigrams (tweets, 10) assert answer [0] == (('!', '!'), 1334) answer2 = freq_bigrams (tweets, 6) assert len(answer2) == 6 assert answer2[5] == (('Happy', 'birthday'), 347) Please implement the freq_skipgrams function to calculate the most frequently used k-skip-n-grams. Your function should return a list of top n tuples, each of the tuples should contain a k-skip-n-gram tuple (such as 'Happy', 'Birthday', '9') and its number of occurrences. : def freq_skipgrams (tweets, n, k, top_n): skipgram_counter = Counter() # YOUR CODE HERE raise Not ImplementedError() : freq_bigrams (tweets, 10) : # test answer = freq_skipgrams (tweets, n=3, k=2, top_n=10) assert answer [0] == (('!', '!', '!'), 511) Complete the shingling_jaccard_similarity function to compute the similarity score between two pieces of text using the shingling approach. Specifically, you should (1) represent both text sequences as sets of overlapping n-grams (n specified as an argument) and (2) compute the Jaccard similarity between the two sets. We have implemented a jaccard_similarity function for your convenience. Hint: 1. You may use the nltk.ngrams API to obtain the n-grams. 2. The nltk.ngrams API returns a iterator of tuples. you may wrap it up with list() to collect the n-grams as a list. You may checkout how we use nltk.bigrams in the beginning of this assignment as example. : def jaccard_similarity(list_x, list_y): set_x = set(list_x) set_y = set(list_y) intersection = set_x.intersection(set_y) union = set_x.union(set_y) return len(intersection) / len(union) if len(union) > 0 else : tokenizer = nltk. tokenize.casual. TweetTokenizer() def shingling_jaccard_similarity(text_x, text_y, n): # YOUR CODE HERE raise NotImplementedError() return sim_score x = "to be or not to be" y = "not be or not to be" z = "be or not to not be" print(shingling_jaccard_similarity(x,y, 3)) print(shingling_jaccard_similarity(x,z, 3)) assert abs(shingling_jaccard_similarity("to be or not to be", "not be or not to be", 3) - 0.6) 0 else : tokenizer = nltk. tokenize.casual. TweetTokenizer() def shingling_jaccard_similarity(text_x, text_y, n): # YOUR CODE HERE raise NotImplementedError() return sim_score x = "to be or not to be" y = "not be or not to be" z = "be or not to not be" print(shingling_jaccard_similarity(x,y, 3)) print(shingling_jaccard_similarity(x,z, 3)) assert abs(shingling_jaccard_similarity("to be or not to be", "not be or not to be", 3) - 0.6)
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts