

Question: Imputation is the process of replacing missing data with substituted values. Let's assume we want to keep columns where 5% or less of the

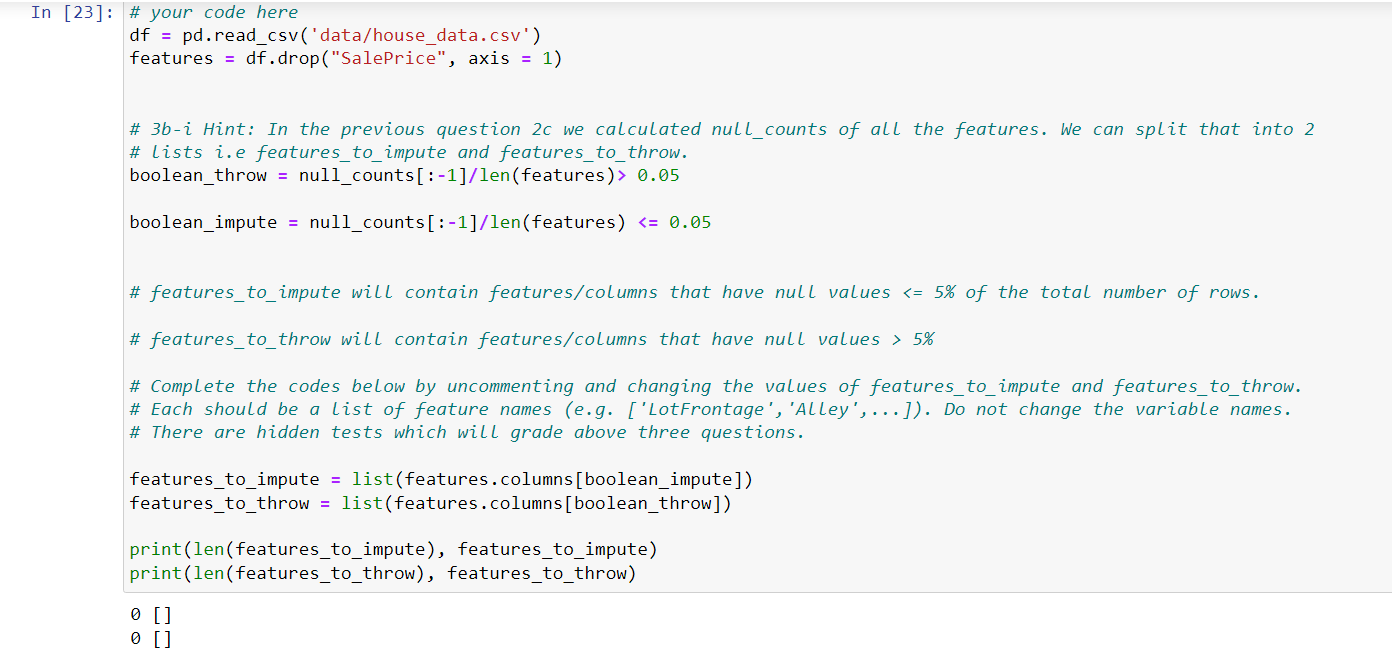
Imputation is the process of replacing missing data with substituted values. Let's assume we want to keep columns where 5% or less of the values are null (keep and impute) and discard any column where more than 5% of the values are null (throw). Treat the string type "None" as a category and not a null value. 3b-i) According to above condition (5% threshold), how many features can be kept and imputed? [5 pts] 3b-ii) Which columns have null values 5% or less of total, so we can impute? [5 pts] 3b-iii) Which columns have null vaues more than 5% of total, so we should throw? [5 pts] In [23] # your code here df pd.read_csv('data/house_data.csv") features df.drop("SalePrice", axis=1) # 3b-i Hint: In the previous question 2c we calculated null_counts of all the features. We can split that into 2 # lists i.e features_to_impute and features_to_throw. boolean throw null_counts[:-1]/len(features)> 0.05 boolean impute = null_counts[:-1]/len(features)
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts