

Question: In Python3: mapreduce Please complete the mapper.py and reducer.py In the final section of the lab, you are given two data files in comma-separated value
In Python3: mapreduce
Please complete the mapper.py and reducer.py
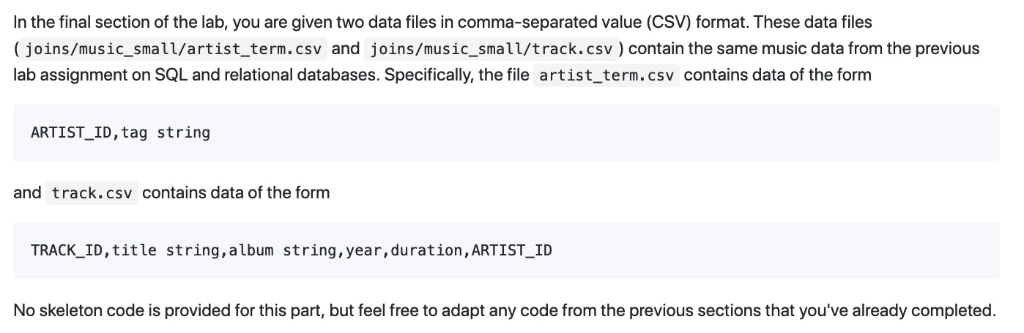
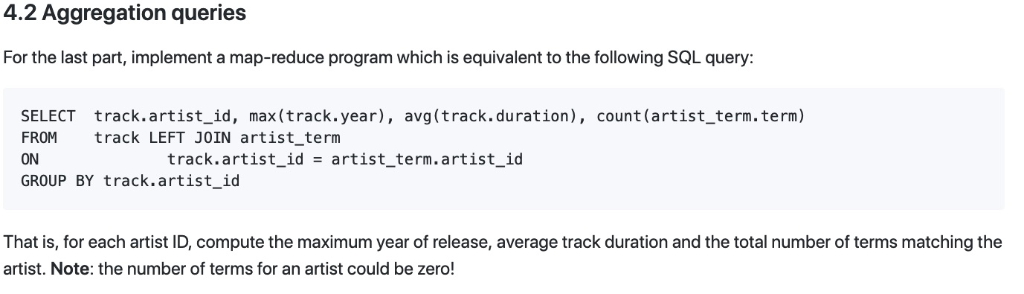
In the final section of the lab, you are given two data files in comma-separated value (CSV) format. These data files (joins/music_small/artist_term.csv and joins/music_small/track.csv) contain the same music data from the previous lab assignment on SQL and relational databases. Specifically, the file artist_term.csv contains data of the form ARTIST-ID, tag string and track.csv contains data of the form TRACK_ID, title string,album string, year,duration, ARTIST_ID No skeleton code is provided for this part, but feel free to adapt any code from the previous sections that you've already completed. 4.2 Aggregation queries For the last part, implement a map-reduce program which is equivalent to the following SQL query SELECT track.artist_id, max(track.year), avg(track.duration), count (artist_term.term) FROM track LEFT JOIN artist_term ON GROUP BY track.artist_id track.artist_id- artist_term.artist id That is, for each artist ID, compute the maximum year of release, average track duration and the total number of terms matching the artist. Note: the number of terms for an artist could be zero! In the final section of the lab, you are given two data files in comma-separated value (CSV) format. These data files (joins/music_small/artist_term.csv and joins/music_small/track.csv) contain the same music data from the previous lab assignment on SQL and relational databases. Specifically, the file artist_term.csv contains data of the form ARTIST-ID, tag string and track.csv contains data of the form TRACK_ID, title string,album string, year,duration, ARTIST_ID No skeleton code is provided for this part, but feel free to adapt any code from the previous sections that you've already completed. 4.2 Aggregation queries For the last part, implement a map-reduce program which is equivalent to the following SQL query SELECT track.artist_id, max(track.year), avg(track.duration), count (artist_term.term) FROM track LEFT JOIN artist_term ON GROUP BY track.artist_id track.artist_id- artist_term.artist id That is, for each artist ID, compute the maximum year of release, average track duration and the total number of terms matching the artist. Note: the number of terms for an artist could be zero
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts