

Question: It has to do with Python3 To decode the secret messages, you need an approach that will incrementally improve on an existing solution. In other
It has to do with Python3
To decode the secret messages, you need an approach that will incrementally improve on an existing solution. In other words, you need to write a hill-climbing program. That means we need to formulate this task as an optimization problem.
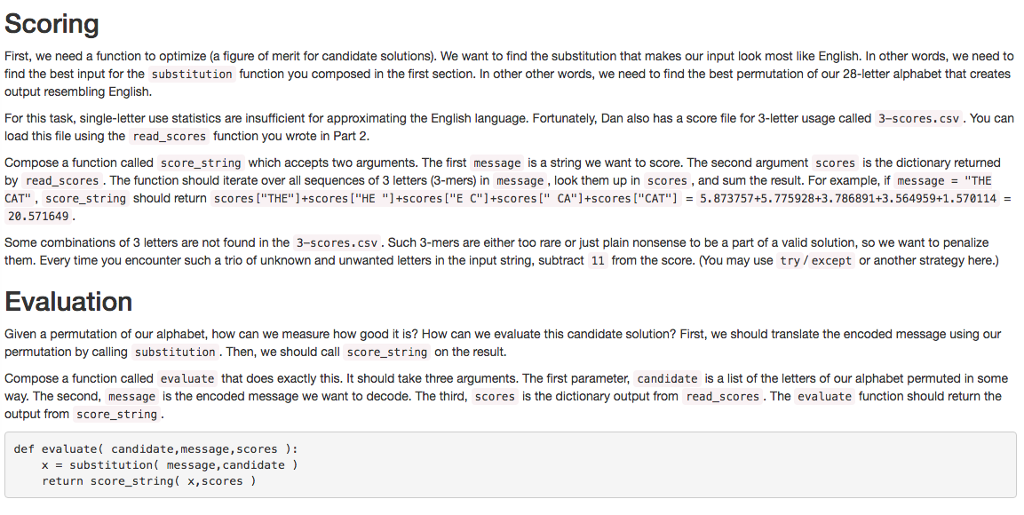
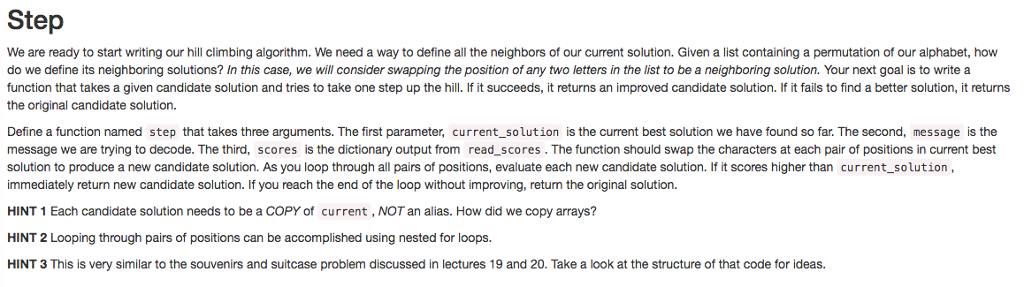
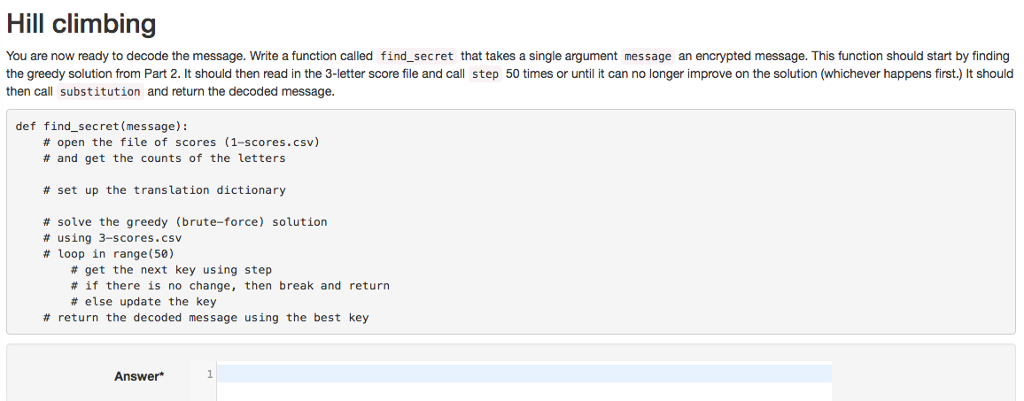
Scoring First, we need a function to optimize (a figure of merit for candidate solutions). We want to find the substitution that makes our input look most like English. In other words, we need to find the best input for the substitution function you composed in the first section. In other other words, we need to find the best permutation of our 28-letter alphabet that creates output resembling English. For this task, single-letter use statistics are insufficient for approximating the English language. Fortunately, Dan also has a score file for 3-letter usage called 3-scores.csv. You can load this file using the read scores function you wrote in Part 2 Compose a function called score string which accepts two arguments. The first message is a string we want to score. The second argument scores is the dictionary returned by read scores The function should iterate over all sequences of 3 letters (3-mers in message look them up in scores and sum the result. For example, if message THE CAT score string should return scores ["THE "J+scores ["HE +scores I''E C"]+scores CA"]+scores ["CAT 5.873757+5.775928+3.786891+3.564959+1.570114 20.571649 Some combinations of 3 letters are not found in the 3-scores. csv. Such 3-mers are either too rare or just plain nonsense to be a part of a valid solution, so we want to penalize them. Every time you encounter such a trio of unknown and unwanted letters in the input string, subtract 11 from the score. You may use try /except or another strategy here.) Evaluation Given a permutation of our alphabet, how can we measure how good it is? How can we evaluate this candidate solution? First, we should translate the encoded message using our permutation by calling substitution Then, we should call score string on the result. Compose a function called evaluate that does exactly this. It should take three arguments. The first parameter, candidate is a list of the letters of our alphabet permuted in some way. The second, message is the encoded message we want to decode. The third, scores is the dictionary output from read scores.The evaluate function should return the output from score string def evaluate candidate, message, scores x substitution message, candidate return score string x,scores Scoring First, we need a function to optimize (a figure of merit for candidate solutions). We want to find the substitution that makes our input look most like English. In other words, we need to find the best input for the substitution function you composed in the first section. In other other words, we need to find the best permutation of our 28-letter alphabet that creates output resembling English. For this task, single-letter use statistics are insufficient for approximating the English language. Fortunately, Dan also has a score file for 3-letter usage called 3-scores.csv. You can load this file using the read scores function you wrote in Part 2 Compose a function called score string which accepts two arguments. The first message is a string we want to score. The second argument scores is the dictionary returned by read scores The function should iterate over all sequences of 3 letters (3-mers in message look them up in scores and sum the result. For example, if message THE CAT score string should return scores ["THE "J+scores ["HE +scores I''E C"]+scores CA"]+scores ["CAT 5.873757+5.775928+3.786891+3.564959+1.570114 20.571649 Some combinations of 3 letters are not found in the 3-scores. csv. Such 3-mers are either too rare or just plain nonsense to be a part of a valid solution, so we want to penalize them. Every time you encounter such a trio of unknown and unwanted letters in the input string, subtract 11 from the score. You may use try /except or another strategy here.) Evaluation Given a permutation of our alphabet, how can we measure how good it is? How can we evaluate this candidate solution? First, we should translate the encoded message using our permutation by calling substitution Then, we should call score string on the result. Compose a function called evaluate that does exactly this. It should take three arguments. The first parameter, candidate is a list of the letters of our alphabet permuted in some way. The second, message is the encoded message we want to decode. The third, scores is the dictionary output from read scores.The evaluate function should return the output from score string def evaluate candidate, message, scores x substitution message, candidate return score string x,scores
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts