

Question: LinearProbingAbstractHashST class has two sub-classes, LinearProbingHashST1 and LinearProbingHashST2 (source code provided), which differ in hash function implementation. LinearProbingHashST2 implementation tries to distribute keys better when
LinearProbingAbstractHashST class has two sub-classes, LinearProbingHashST1 and LinearProbingHashST2 (source code provided), which differ in hash function implementation. LinearProbingHashST2 implementation tries to distribute keys better when table size is divisible by power of 2. a) Implement the following method inside LinearProbingAbstractHashST.
 b) Use LinearProbingHashSTTest to test your implementation, and provide the results in 4 tables each similar to the following. Also, provide your observation with the results.
b) Use LinearProbingHashSTTest to test your implementation, and provide the results in 4 tables each similar to the following. Also, provide your observation with the results. 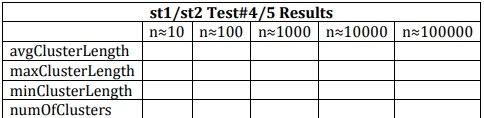 Source Code: LinearProbingAbstractHashST: (
Source Code: LinearProbingAbstractHashST: (
import java.util.Map;
import java.util.TreeMap;
public abstract class LinearProbingAbstractHashST
protected int n; // number of key-value pairs in the table
protected int m = 16; // size of linear-probing table
protected Key[] keys; // the keys
protected Value[] vals; // the values
@SuppressWarnings("unchecked")
public LinearProbingAbstractHashST() {
n=0;
keys = (Key[]) new Comparable[m];
vals = (Value[]) new Object[m];
}
@SuppressWarnings("unchecked")
public LinearProbingAbstractHashST(int capacity) {
n=0;
m = capacity;
keys = (Key[]) new Comparable[m];
vals = (Value[]) new Object[m];
}
abstract protected int hash(Key key);
public Value get(Key key) {
for (int i = hash(key); keys[i] != null; i = (i + 1) % m) {
if (keys[i].equals(key))
return vals[i];
}
return null;
}
public void put(Key key, Value val) {
//ensures that the table is at most one-half full
if (n >= m / 2) resize(2 * m);
int i;
for (i = hash(key); keys[i] != null; i = (i + 1) % m) {
// search hit, replace the value
if (keys[i].equals(key)) {
vals[i] = val;
return;
}
}
// search miss, insert the new key value pair
keys[i] = key;
vals[i] = val;
n++;
}
abstract protected void resize(int cap);
public void delete(Key key) {
if (!contains(key)) return;
int i = hash(key);
while (!key.equals(keys[i])) {
i = (i + 1) % m;
}
keys[i] = null;
vals[i] = null;
i = (i + 1) % m;
while (keys[i] != null) {
Key keyToRedo = keys[i];
Value valToRedo = vals[i];
keys[i] = null;
vals[i] = null;
n--;
put(keyToRedo, valToRedo);
i = (i + 1) % m;
}
n--;
//ensure that the table is at least one-eighth full
if (n > 0 && n == m / 8) {
resize(m / 2);
}
}
public boolean contains(Key key) {
return (get(key) != null);
}
@Override
public boolean isEmpty() {
return n==0;
}
@Override
public int size() {
return n;
}
public int getCapacity() {
return m;
}
@Override
public Iterable
// unimplemented
return null;
}
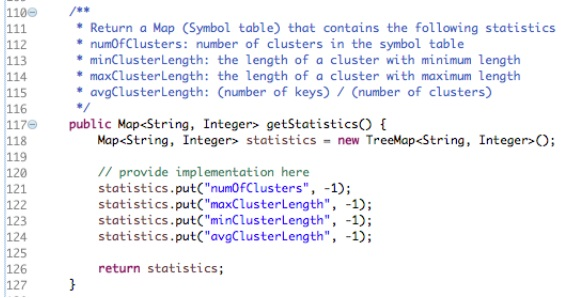
/**
* Return a Map (Symbol table) that contains the following statistics
* numOfClusters: number of clusters in the symbol table
* minClusterLength: the length of a cluster with minimum length
* maxClusterLength: the length of a cluster with maximum length
* avgClusterLength: (number of keys) / (number of clusters)
*/
public Map
Map
// provide implementation here
statistics.put("numOfClusters", -1);
statistics.put("maxClusterLength", -1);
statistics.put("minClusterLength", -1);
statistics.put("avgClusterLength", -1);
return statistics;
}
}
)
LinearProbingHashST1: (
public class LinearProbingHashST1
public LinearProbingHashST1(int m) {
super(m);
}
@Override
protected int hash(Key key) {
return (key.hashCode() & 0x7fffffff) % m;
}
@Override
protected void resize(int cap) {
LinearProbingHashST1
t = new LinearProbingHashST1
// insert key value pairs into the new table
for (int i = 0; i
if (keys[i] != null) {
t.put(keys[i], vals[i]);
}
}
// copy the new table fields to the existing table
keys = t.keys;
vals = t.vals;
m = t.m;
}
}
)
LinearProbingHashST2: (
public class LinearProbingHashST2
static int[] primes =
{0, 0, 0, 0, 0, 31, 61, 127, 251, 509, 1021,
2039, 4093, 8191, 16381, 32749, 65521, 131071, 262139, 524287, 1048573,
2097143, 4194301, 8388593, 16777213, 33554393, 67108859, 134217689, 268435399, 536870909, 1073741789,
2147483647};
public LinearProbingHashST2(int m) {
super(m);
}
@Override
public int hash(Key key) {
int t = key.hashCode() & 0x7fffffff;
int lgm = (int) (Math.log(m)/Math.log(2));
if (lgm
t = t % primes[lgm+5];
}
return (t % m);
}
@Override
protected void resize(int cap) {
LinearProbingHashST2
t = new LinearProbingHashST2
// insert key value pairs into the new table
for (int i = 0; i
if (keys[i] != null) {
t.put(keys[i], vals[i]);
}
}
// copy the new table fields to the existing table
keys = t.keys;
vals = t.vals;
m = t.m;
}
}
)
* Return a Map (Symbol table) that contains the following statistics numOfClusters: number of clusters in the symbol table minClusterLength: the length of a cluster with minimum length maxClusterLength: the length of a cluster with maximum length avgClusterLength: (number of keys)Cnumber of clusters) 112 113 114 115 116 117 public Map
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts