

Question: Load the handwritten zip code digits data from the ElemStatLearn package. Question 2 (k-NN for classification) 45 points] Consider again the zip code digits data.
Load the handwritten zip code digits data from the ElemStatLearn package. 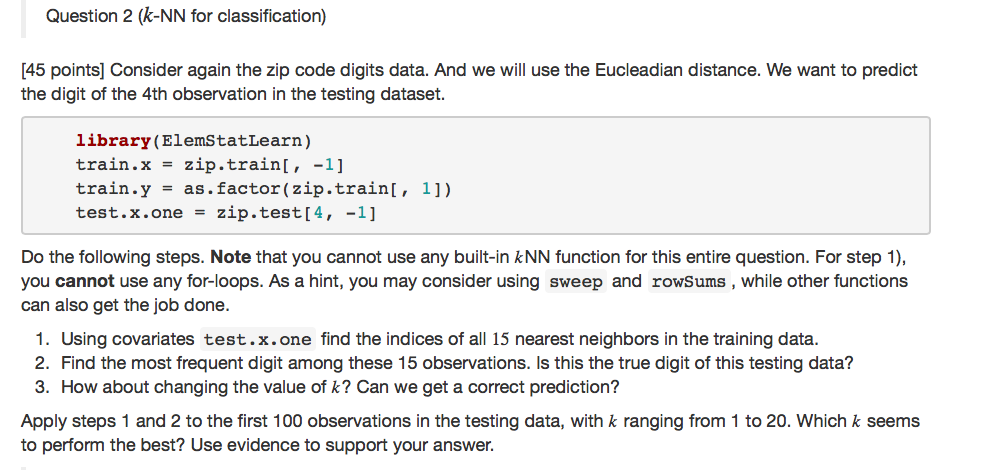
Question 2 (k-NN for classification) 45 points] Consider again the zip code digits data. And we will use the Eucleadian distance. We want to predict the digit of the 4th observation in the testing dataset. library (ElemStatLearn) train.x-zip.trainl, -1] train.y-as.factor (zip.trainl, 1]) test.x.one - zip.test[4, -1] Do the following steps. Note that you cannot use any built-in kNN function for this entire question. For step 1), you cannot use any for-loops. As a hint, you may consider using sweep and rowSums, while other functions can also get the job done. Using covariates test.x.one find the indices of all 15 nearest neighbors in the training data 2. Find the most frequent digit among these 15 observations. Is this the true digit of this testing data? 3. How about changing the value of k? Can we get a correct prediction? Apply steps 1 and 2 to the first 100 observations in the testing data, with k ranging from 1 to 20. Which k seems to perform the best? Use evidence to support your answer. Question 2 (k-NN for classification) 45 points] Consider again the zip code digits data. And we will use the Eucleadian distance. We want to predict the digit of the 4th observation in the testing dataset. library (ElemStatLearn) train.x-zip.trainl, -1] train.y-as.factor (zip.trainl, 1]) test.x.one - zip.test[4, -1] Do the following steps. Note that you cannot use any built-in kNN function for this entire question. For step 1), you cannot use any for-loops. As a hint, you may consider using sweep and rowSums, while other functions can also get the job done. Using covariates test.x.one find the indices of all 15 nearest neighbors in the training data 2. Find the most frequent digit among these 15 observations. Is this the true digit of this testing data? 3. How about changing the value of k? Can we get a correct prediction? Apply steps 1 and 2 to the first 100 observations in the testing data, with k ranging from 1 to 20. Which k seems to perform the best? Use evidence to support your
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts