

Question: MapReduce is a widely-used programming model for data processing for modern applications such as business analytics and deep learning. A powerful aspect of the MapReduce

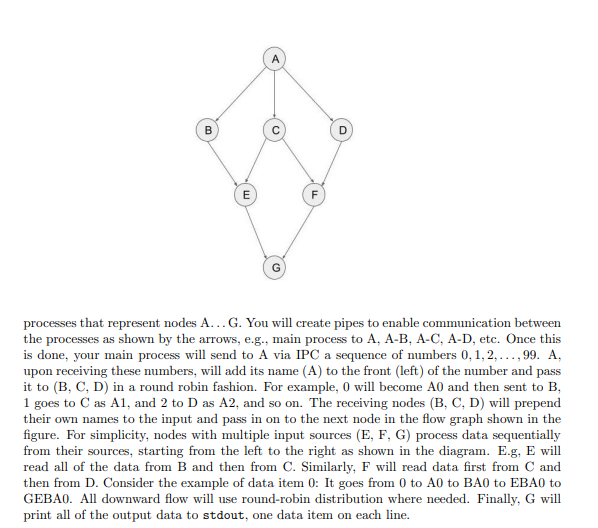
MapReduce is a widely-used programming model for data processing for modern applications such as business analytics and deep learning. A powerful aspect of the MapReduce model is that it can distribute information across many computers and this achieves scale. This is desirable, because to solve a bigger problem, all you have to do is add more computers. In this question, we will try to learn some of the basics of the MapReduce model, especially how it distributes data between different computers. Consider the following graph, where nodes A...G represent different computers. For this question, assume each of the nodes is a process (created with our friend, the fork() call). Data is sent to A, which then distributes, i.e., maps in the MapReduce vocabulary, the data to the nodes in the next stage, here (B, C, D). Each of the nodes then processes the incoming data, and further gathers, i.e., reduces, the data to the next stage, here represented by nodes (E, F). In real MapReduce systems, this reduction may include sorting of data etc., but you can assume it to be a simple processing step for the purposes of this problem. Finally, the last node (G) combines and merges all of the data and outputs the results. This completes the processing cycle. Do note that any of the stages (B, C, D) or (E, F) could be scaled by adding more nodes to it. Supporting such scaling is however not required for this question. 1. (12 pts) You will write a program mapreduce.c that implements the basic data flow rep- resented by the above figure using Unix pipes. Your program acting as the parent will fork B D E F processes that represent nodes A... G. You will create pipes to enable communication between the processes as shown by the arrows, e.g., main process to A, A-B, A-C, A-D, etc. Once this is done, your main process will send to A via IPC a sequence of numbers 0,1,2,...,99. A, upon receiving these numbers, will add its name (A) to the front (left) of the number and pass it to (B, C, D) in a round robin fashion. For example, 0 will become A0 and then sent to B, 1 goes to C as A1, and 2 to D as A2, and so on. The receiving nodes (B, C, D) will prepend their own names to the input and pass in on to the next node in the flow graph shown in the figure. For simplicity, nodes with multiple input sources (E, F, G) process data sequentially from their sources, starting from the left to the right as shown in the diagram. E.g, E will read all of the data from B and then from C. Similarly, F will read data first from C and then from D. Consider the example of data item 0: It goes from 0 to A0 to BAO to EBAO to GEBAO. All downward flow will use round-robin distribution where needed. Finally, G will print all of the output data to stdout, one data item on each line. MapReduce is a widely-used programming model for data processing for modern applications such as business analytics and deep learning. A powerful aspect of the MapReduce model is that it can distribute information across many computers and this achieves scale. This is desirable, because to solve a bigger problem, all you have to do is add more computers. In this question, we will try to learn some of the basics of the MapReduce model, especially how it distributes data between different computers. Consider the following graph, where nodes A...G represent different computers. For this question, assume each of the nodes is a process (created with our friend, the fork() call). Data is sent to A, which then distributes, i.e., maps in the MapReduce vocabulary, the data to the nodes in the next stage, here (B, C, D). Each of the nodes then processes the incoming data, and further gathers, i.e., reduces, the data to the next stage, here represented by nodes (E, F). In real MapReduce systems, this reduction may include sorting of data etc., but you can assume it to be a simple processing step for the purposes of this problem. Finally, the last node (G) combines and merges all of the data and outputs the results. This completes the processing cycle. Do note that any of the stages (B, C, D) or (E, F) could be scaled by adding more nodes to it. Supporting such scaling is however not required for this question. 1. (12 pts) You will write a program mapreduce.c that implements the basic data flow rep- resented by the above figure using Unix pipes. Your program acting as the parent will fork B D E F processes that represent nodes A... G. You will create pipes to enable communication between the processes as shown by the arrows, e.g., main process to A, A-B, A-C, A-D, etc. Once this is done, your main process will send to A via IPC a sequence of numbers 0,1,2,...,99. A, upon receiving these numbers, will add its name (A) to the front (left) of the number and pass it to (B, C, D) in a round robin fashion. For example, 0 will become A0 and then sent to B, 1 goes to C as A1, and 2 to D as A2, and so on. The receiving nodes (B, C, D) will prepend their own names to the input and pass in on to the next node in the flow graph shown in the figure. For simplicity, nodes with multiple input sources (E, F, G) process data sequentially from their sources, starting from the left to the right as shown in the diagram. E.g, E will read all of the data from B and then from C. Similarly, F will read data first from C and then from D. Consider the example of data item 0: It goes from 0 to A0 to BAO to EBAO to GEBAO. All downward flow will use round-robin distribution where needed. Finally, G will print all of the output data to stdout, one data item on each line
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts